
Abstract
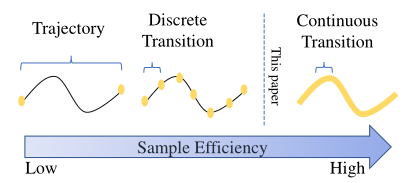
Although deep reinforcement learning (RL) has been successfully applied to a variety of robotic control tasks, it’s still challenging to apply it to real-world tasks, due to the poor sample efficiency. Attempting to overcome this shortcoming, several works focus on reusing the collected trajectory data during the training by decomposing them into a set of policyirrelevant discrete transitions. However, their improvements are somewhat marginal since i) the amount of the transitions is usually small, and ii) the value assignment only happens in the joint states. To address these issues, this paper introduces a concise yet powerful method to construct Continuous Transition, which exploits the trajectory information by exploiting the potential transitions along the trajectory. Specifically, we propose to synthesize new transitions for training by linearly interpolating the consecutive transitions. To keep the constructed transitions authentic, we also develop a discriminator to guide the construction process automatically. Extensive experiments demonstrate that our proposed method achieves a significant improvement in sample efficiency on various complex continuous robotic control problems in MuJoCo and outperforms the advanced modelbased / model-free RL methods. The source code is available.
Framework

Experiment
Conclusion
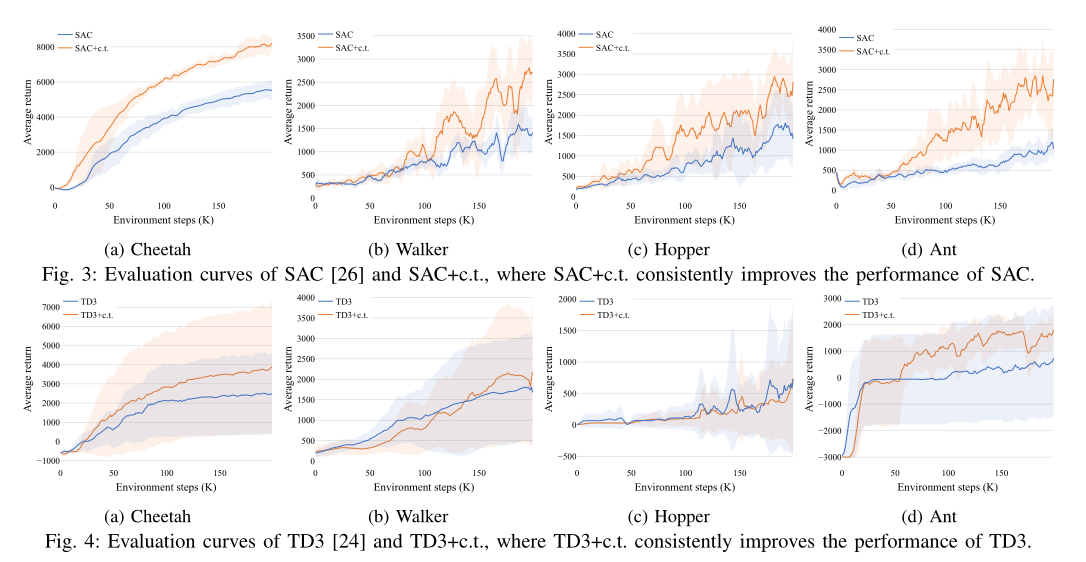
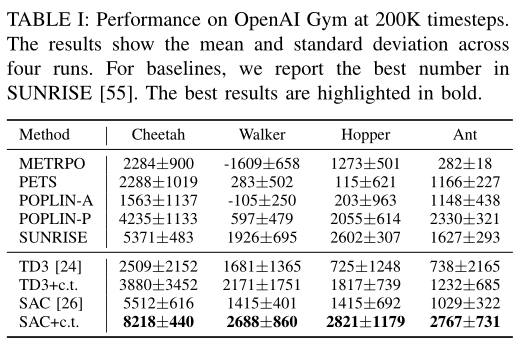
In this paper, we exploited the potential of the intermediate information along the trajectory by constructing continuous transition through linearly interpolating the consecutive discrete transitions. In order to synthesize more authentic transitions, we introduced an energy-based discriminator to auto-tuning the temperature of the beta distribution. Experimental results demonstrated our proposed methods achieve significant improvements on sample efficiency against the compared methods. Considering that our methods are testified in simulated environments, we will extend our work to real robotic control tasks in the future.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab