
Abstract
We propose Stochastic Neural Architecture Search (SNAS), an economical end-to-end solution to Neural Architecture Search (NAS) that trains neural operation parameters and architecture distribution parameters in same round of back-propagation, while maintaining the completeness and differentiability of the NAS pipeline. In this work, NAS is reformulated as an optimization problem on parameters of a joint distribution for the search space in a cell. To leverage the gradient information in generic differentiable loss for architecture search, a novel search gradient is proposed. We prove that this search gradient optimizes the same objective as reinforcement-learning-based NAS, but assigns credits to structural decisions more efficiently. This credit assignment is further augmented with locally decomposable reward to enforce a resource-efficient constraint. In experiments on CIFAR-10, SNAS takes less epochs to find a cell architecture with state-of-the-art accuracy than non-differentiable evolution-based and reinforcement-learning-based NAS, which is also transferable to ImageNet. It is also shown that child networks of SNAS can maintain the validation accuracy in searching, with which attention-based NAS requires parameter retraining to compete, exhibiting potentials to stride towards efficient NAS on big datasets. Keywords: Neural Architecture Search
Problem Description
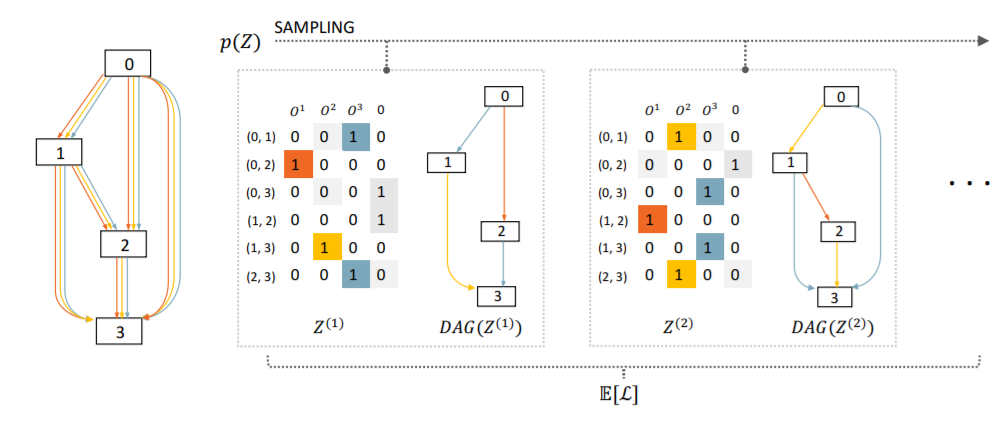
A conceptual visualization for a forward pass within SNAS.
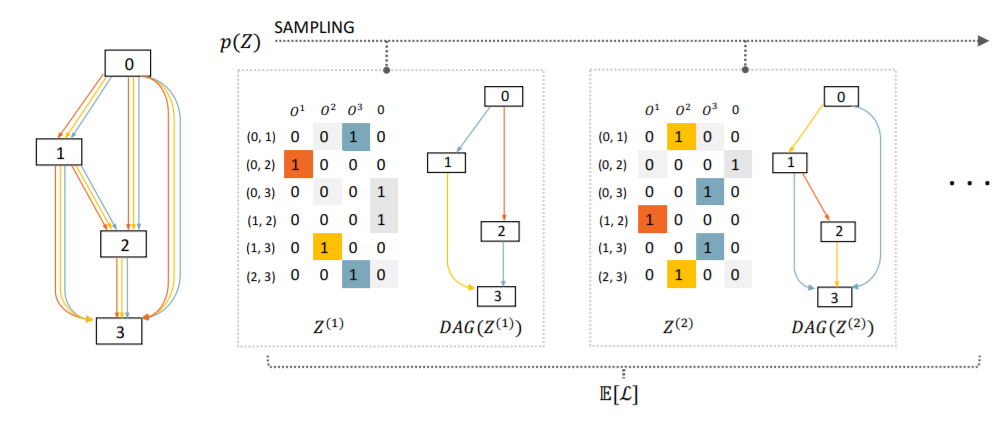
Fig. 1. A conceptual visualization for a forward pass within SNAS. Sampled from p(Z), Z is a matrix whose rows Zi,j are one-hot random variable vectors indicating masks multiplied to edges(i, j) in the DAG. Columns of this matrix correspond to operations Ok. In this example, there are 4 operation candidates, among which the last one is zero, i.e. removing that edge. The objective is the expectation of generic loss L of all child graphs.
Experiment
In our experiments, SNAS shows strong performance compared with DARTS and all other existing NAS methods in terms of test error, model complexity and searching resources. Specifically, SNAS discovers novel convolutional cells achieving 2.85±0.02% test error on CIFAR-10 with only 2.8M parameters, which is better than 3.00±0.14%-3.3M from 1st-order DARTS and 2.89%-4.6M from ENAS. It is also on par with 2.76±0.09%-3.3M from 2nd-order DARTS with fewer parameters. With a more aggressive resource constraint, SNAS discovers even smaller model achieving 3.10±0.04% test error on CIFAR-10 with 2.3M parameters. During the architecture search process, SNAS obtains a validation accuracy of 88% compared to around 70% of ENAS in fewer epochs. When validating the derived child network on CIFAR-10 without finetuning, SNAS maintains the search validation accuracy, significantly outperforming 54.66% by DARTS. These results validate our theory that SNAS is less biased than DARTS. The discovered cell achieves 27.3% top-1 error when transferred to ImageNet (mobile setting), which is comparable to 26.9% by 2nd-order DARTS.
Methodology
The main initiative of SNAS is to build an efficient and economical end-to-end learning system with as little compromise of the NAS pipeline as possible. In this section, we first describe how to sample from the search space for NAS in a cell, and how it motivates a stochastic reformuation for SNAS (Section 2.1). A new optimization objective is provided and the attention-based NAS’s inconsistency is discussed. Then in Section 2.2, we introduce how this discrete search space is relaxed to be continuous to let gradients back-propagate through. In Section 2.3, the search gradient of SNAS is connected to the policy gradient in reinforcement-learning-based NAS (Zoph & Le, 2016; Pham et al., 2018), interpreting SNAS’s credit assignment with contribution analysis. At last, we introduce in Section 2.4 how SNAS automates the topology search to reduce the complexity of child netowrk, as well as how it decomposes this global constraint in the context of credit assignment.
Conclusion
In this work, we presented SNAS, a novel and economical end-to-end neural architecture search framework. The key contribution of SNAS is that by making use of gradient information from generic differentiable loss without sacrificing the completeness of NAS pipeline, stochastic architecture search could be more efficient. This improvement is proved by comparing the credit assigned by the search gradient with reinforcement-learning-based NAS. Augmented by a complexity regularizer, this search gradient trades off testing error and forwarding time. Experiments showed that SNAS searches well on CIFAR-10, whose result could be transferred to ImageNet as well. As a more efficient and less-biased framework, SNAS will serve as a possible candidate for full-fledged NAS on large datasets in the future.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab