
Abstract
In recent years, deep neural network tasks have increasingly relied on high-quality image inputs. With the development of high-resolution representation learning, the task of image dehazing has received significant attention. Previously, many methods collected diverse image data for large-scale training to boost the performance on a target scene. Ignoring the domain gap between different data, former dehazing methods simply adopt multiple datasets for explicit large-scale training, which often makes the methods themselves violated. To address this problem, we propose a novel method of cross-data vision alignment for richer representation learning to improve the existing dehazing methodology. Specifically, we call for the internal and external knowledge should be further adapted in a self-supervised manner to fill up the domain gap. By using cross-data external alignment, the datasets inherit samples from different domains that are firmly aligned, making the model learn more robust and generalizable features. By using the internal augmentation method, the model can fully exploit local information within the images and then obtain more image details. To demonstrate the effectiveness of our proposed method, we conduct training on the natural image dataset (NID). Experimental results show that our method clearly resolves the domain gap in different dehazing datasets and presents a new pipeline for large-scale training in the dehazing task. Our approach significantly outperforms other advanced methods in dehazing and produces dehazed images that are closest to real haze-free images.
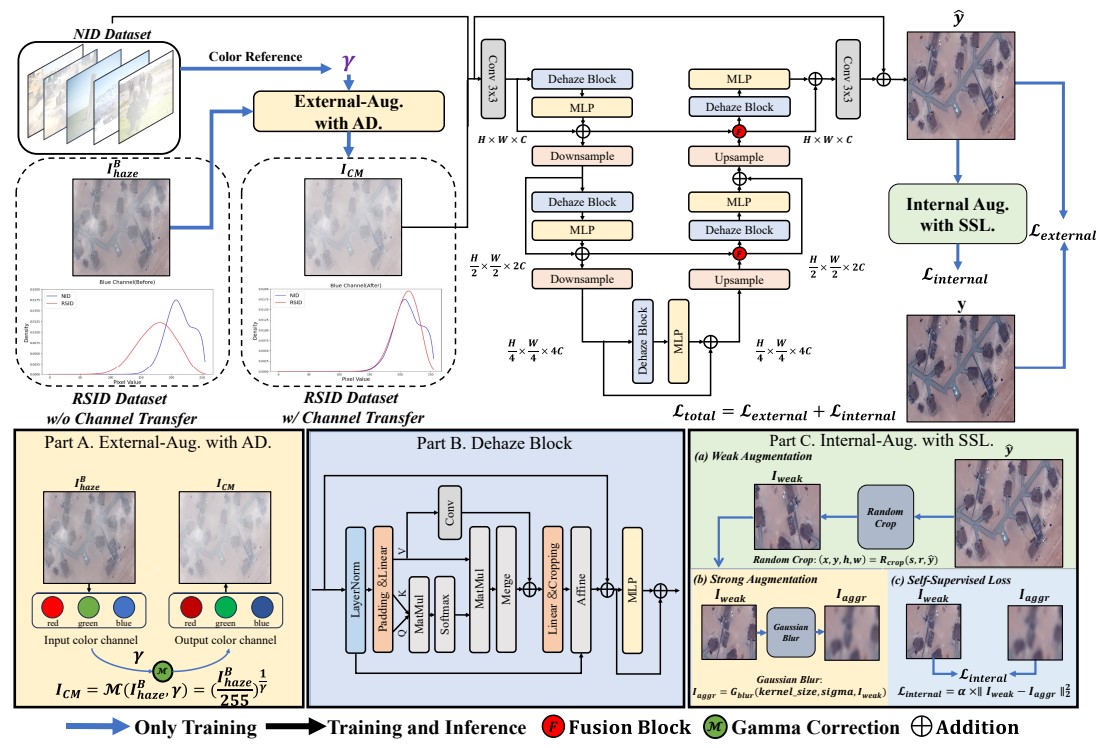
Framework
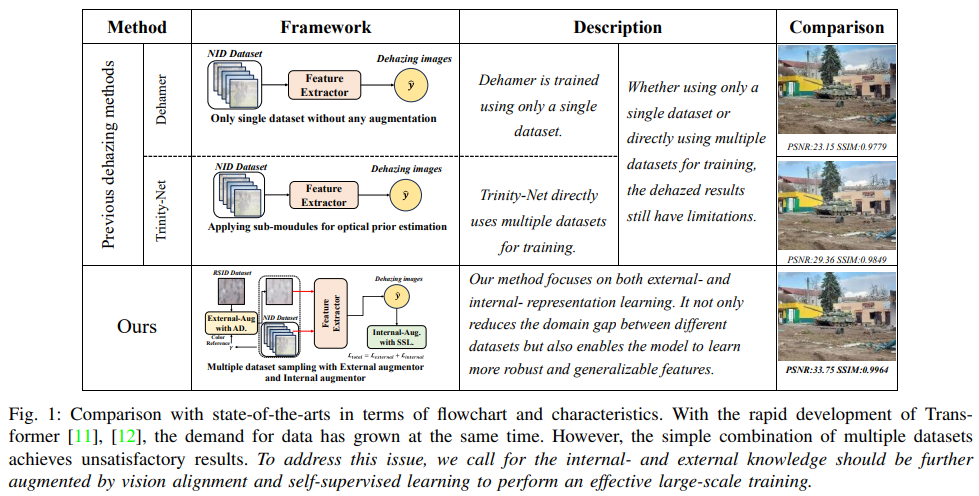
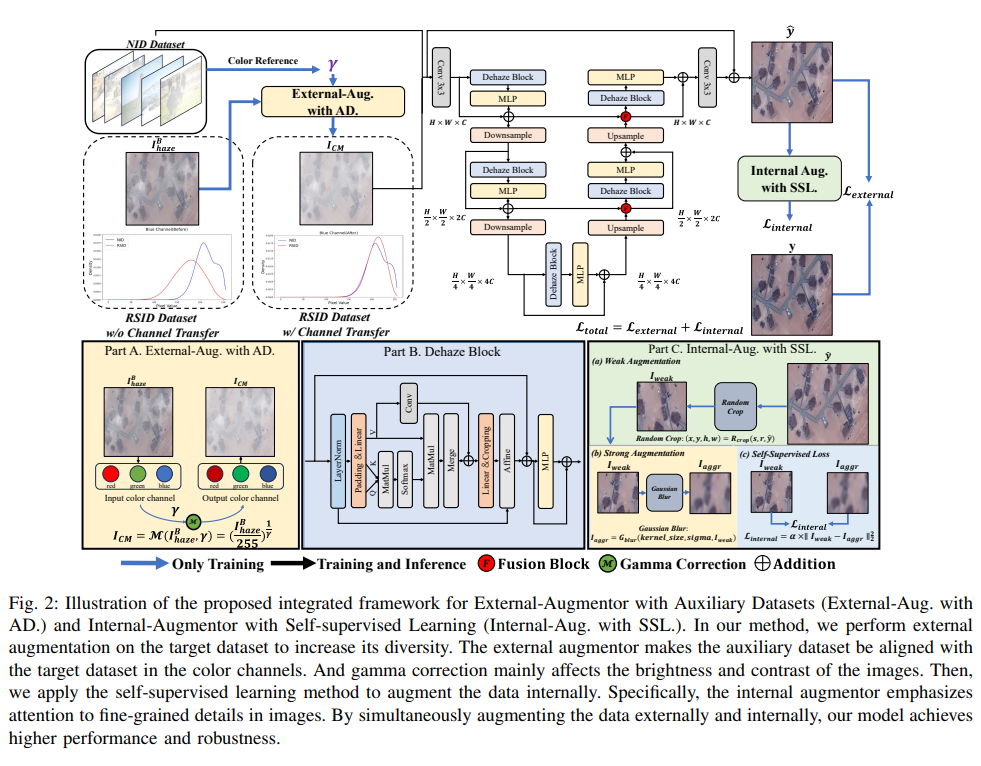







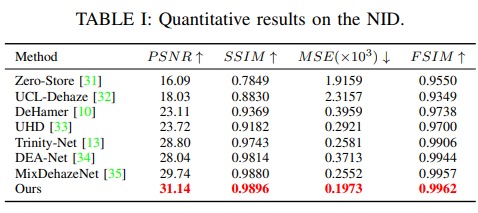
Experiment
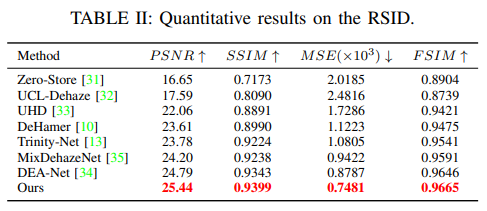
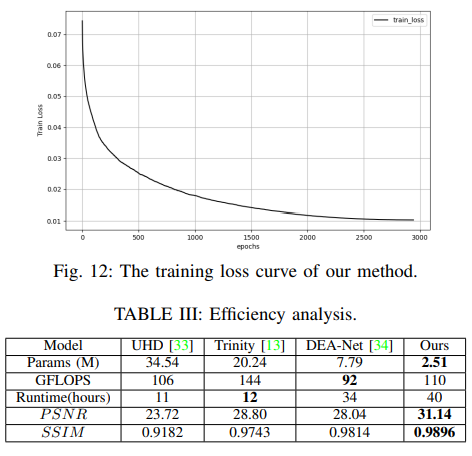
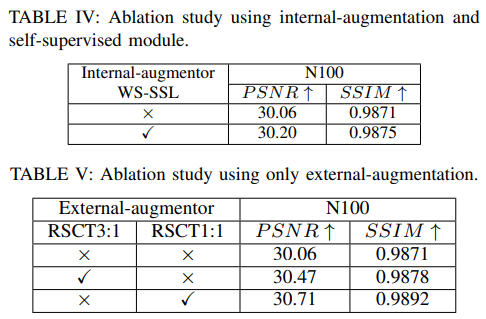
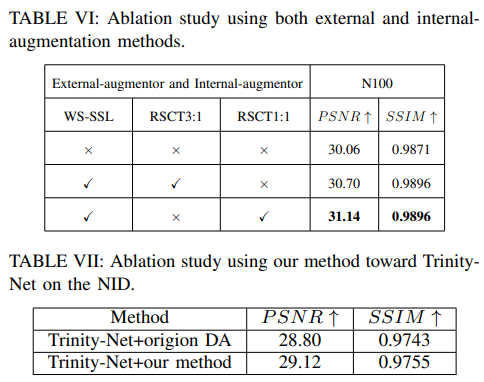
Conclusion
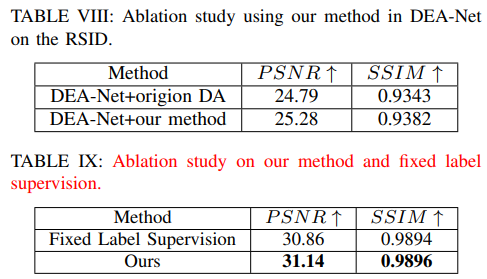
In this paper, we propose a novel method that performs data augmentation separately on the external and internal aspects of the data. Specifically, we achieve external- augmentation and internal- augmentation using weak-to-strong self-supervised learning. Our method leverages data diversity at the external level and further explores internal information to effectively dehaze images.
Although our method achieves superior results in both quantitative and qualitative evaluations, the introduction of augmentation operations has led to an increase in training time compared to other methods. In the future, we will focus on research aimed at improving training efficiency.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab