
Abstract
Infrared and visible image fusion (IVIF) is increasingly applied in critical fields such as video surveillance and autonomous driving systems. Significant progress has been made in deep learning-based fusion methods. However, these models frequently encounter out-of-distribution (OOD) scenes in real-world applications, which severely impact their performance and reliability. Therefore, addressing the challenge of OOD data is crucial for the safe deployment of these models in open-world environments. Unlike existing research, our focus is on the challenges posed by OOD data in real-world applications and on enhancing the robustness and generalization of models. In this paper, we propose an infrared-visible fusion framework based on Multi-View Augmentation. For external data augmentation, Top-k Selective Vision Alignment is employed to mitigate distribution shifts between datasets by performing RGB-wise transformations on visible images. This strategy effectively introduces augmented samples, enhancing the adaptability of the model to complex real-world scenarios. Additionally, for internal data augmentation, self-supervised learning is established using Weak-Aggressive Augmentation. This enables the model to learn more robust and general feature representations during the fusion process, thereby improving robustness and generalization. Extensive experiments demonstrate that the proposed method exhibits superior performance and robustness across various conditions and environments. Our approach significantly enhances the reliability and stability of IVIF tasks in practical applications.
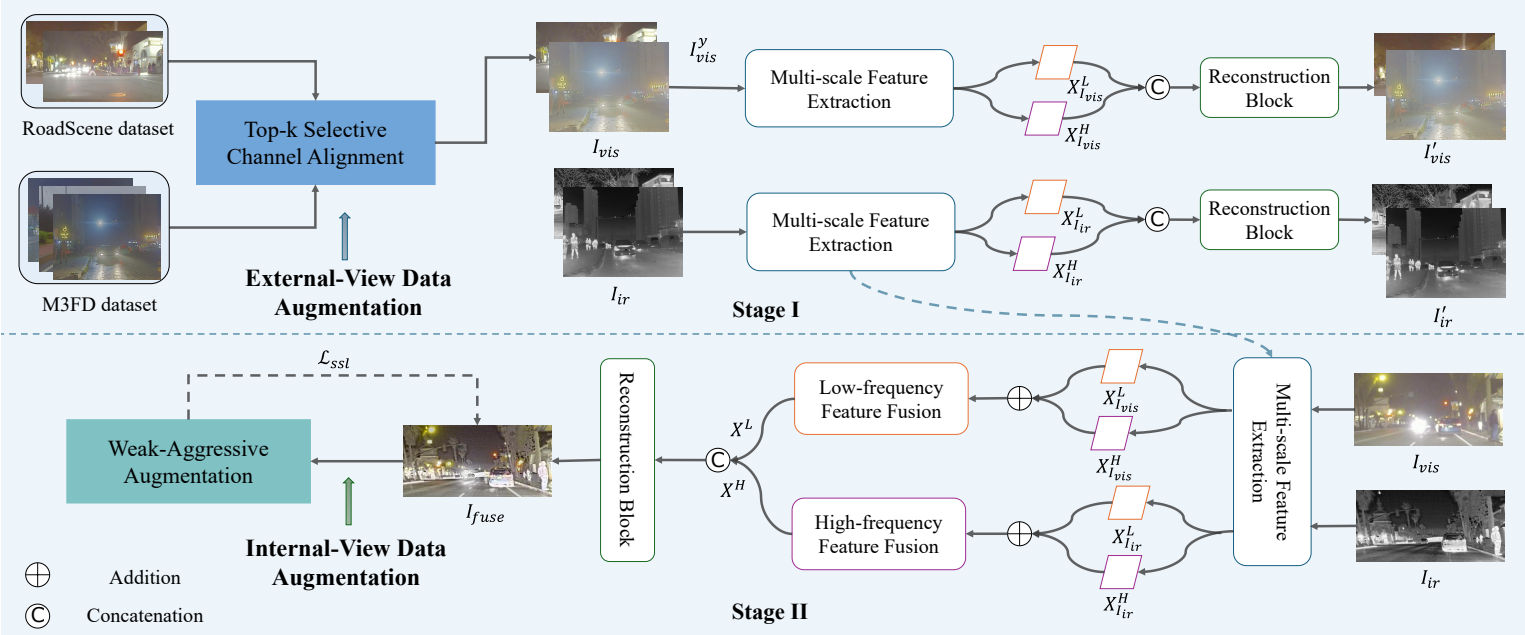
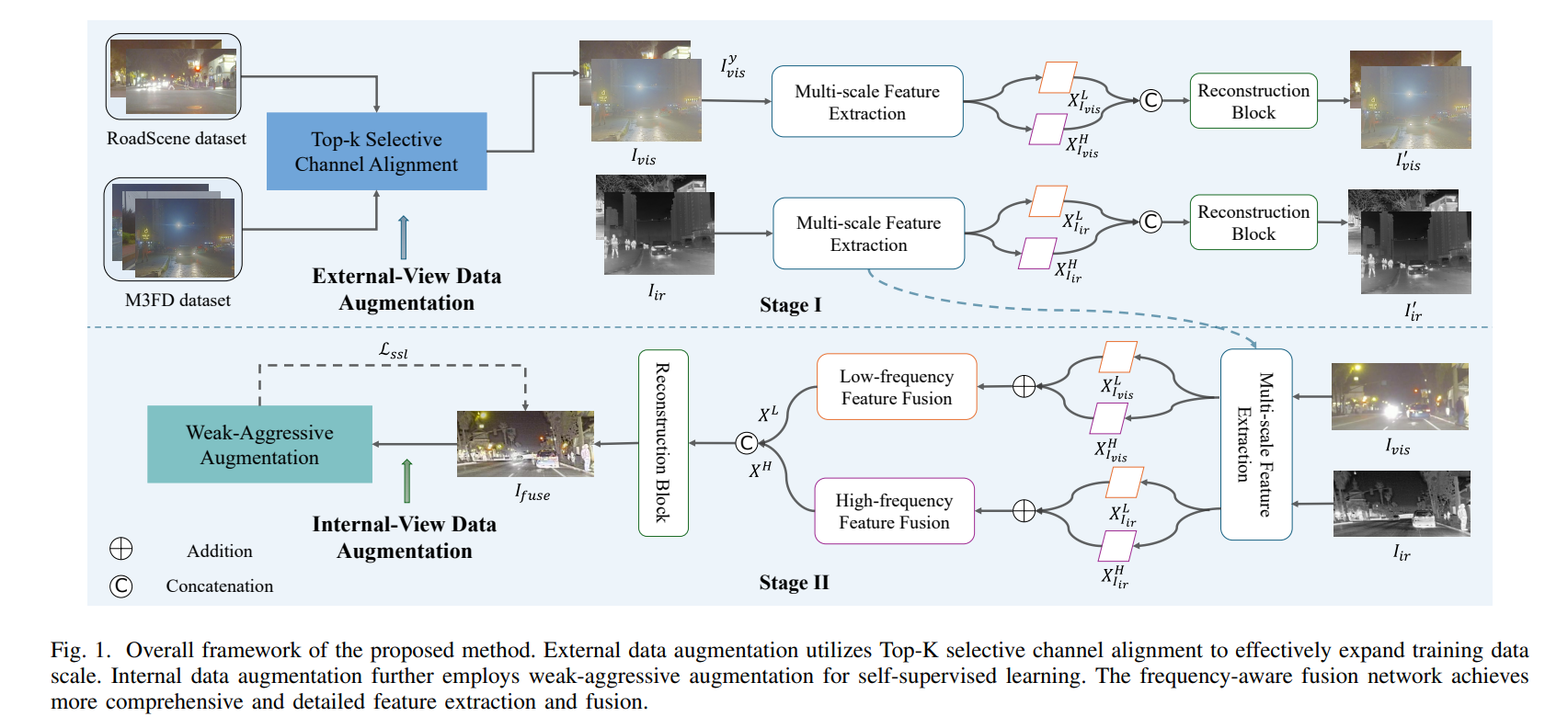
Framework
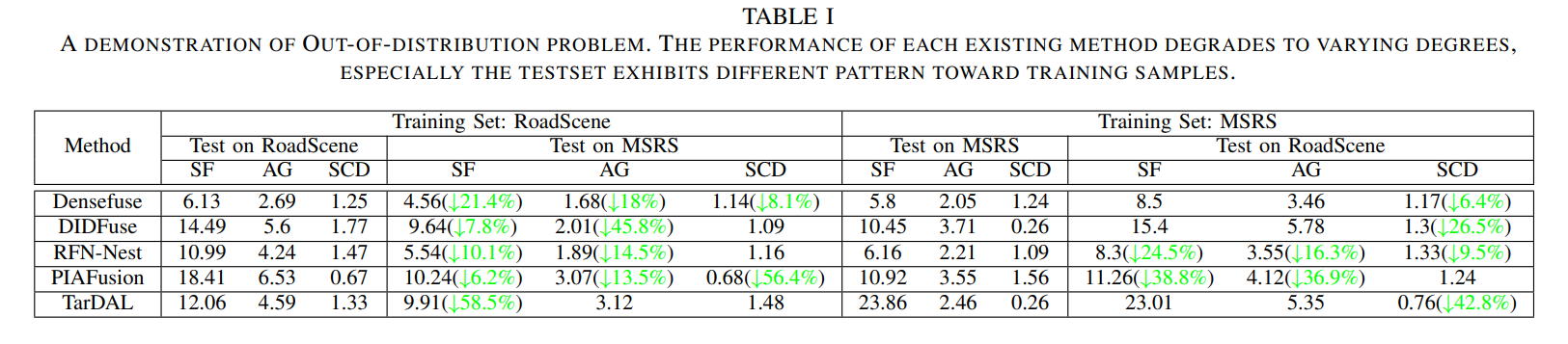
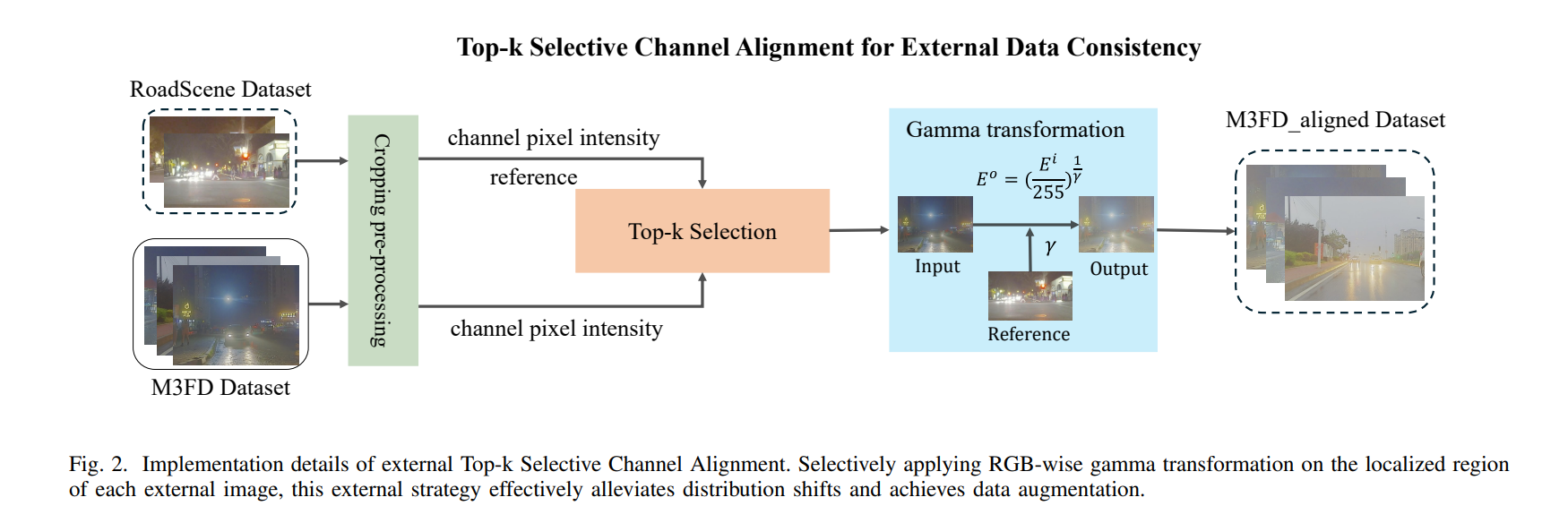
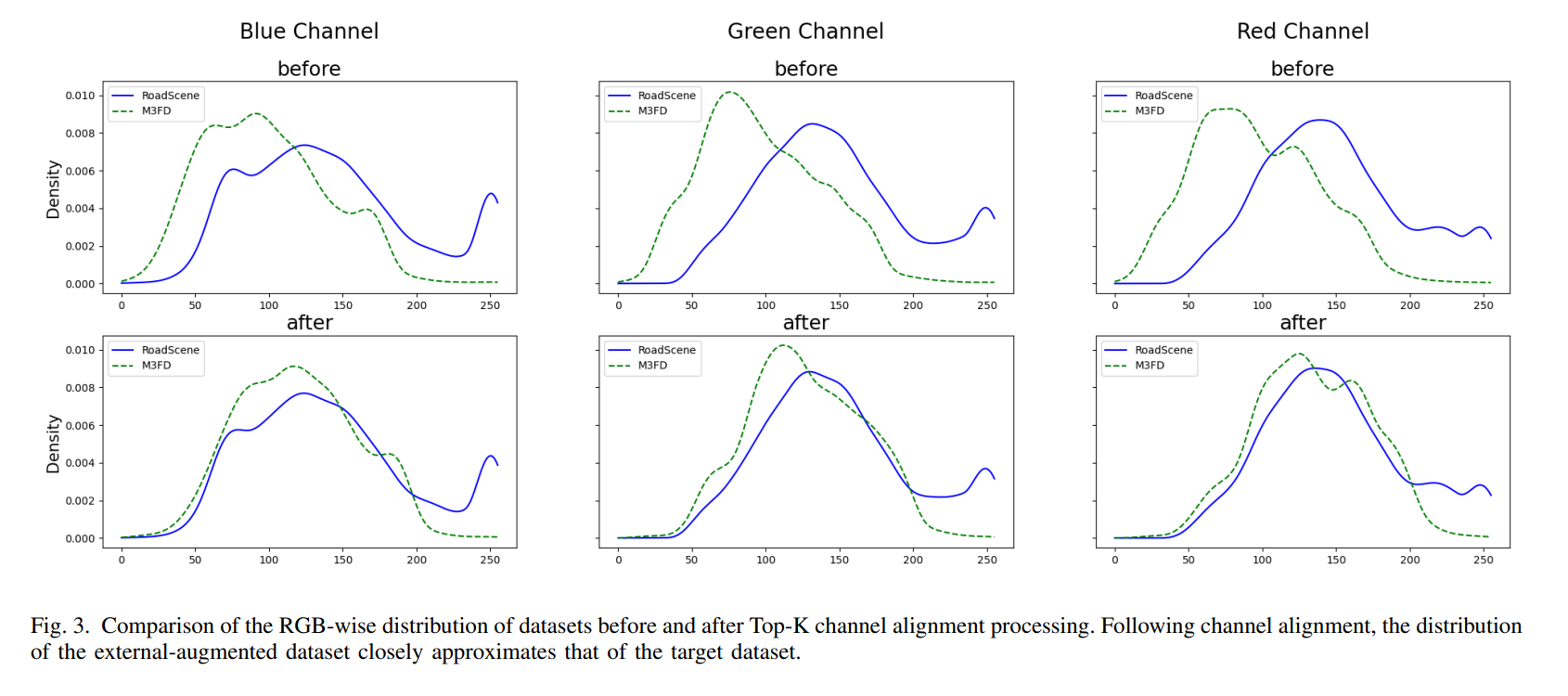

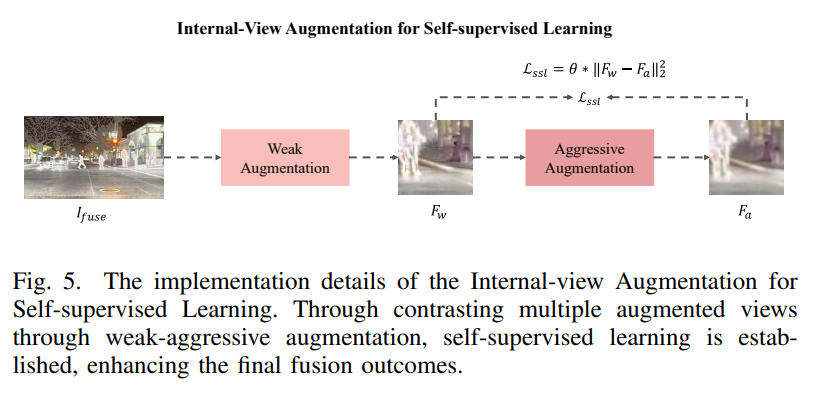
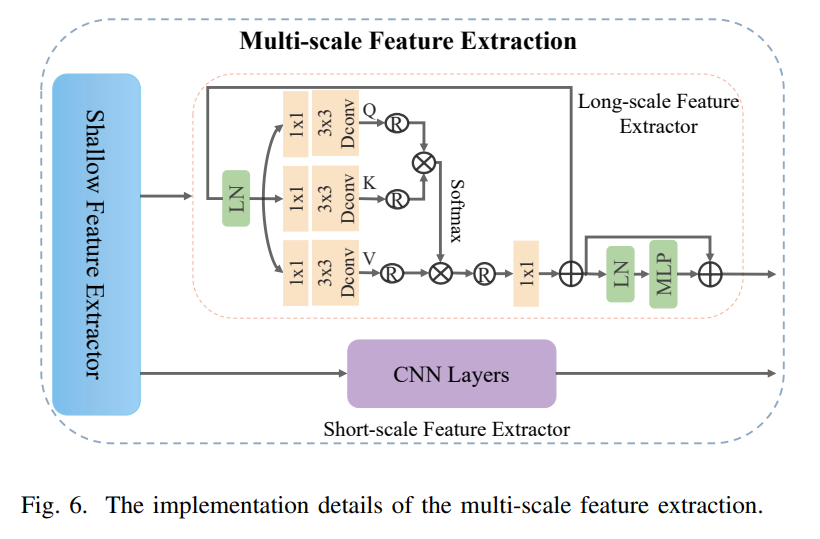
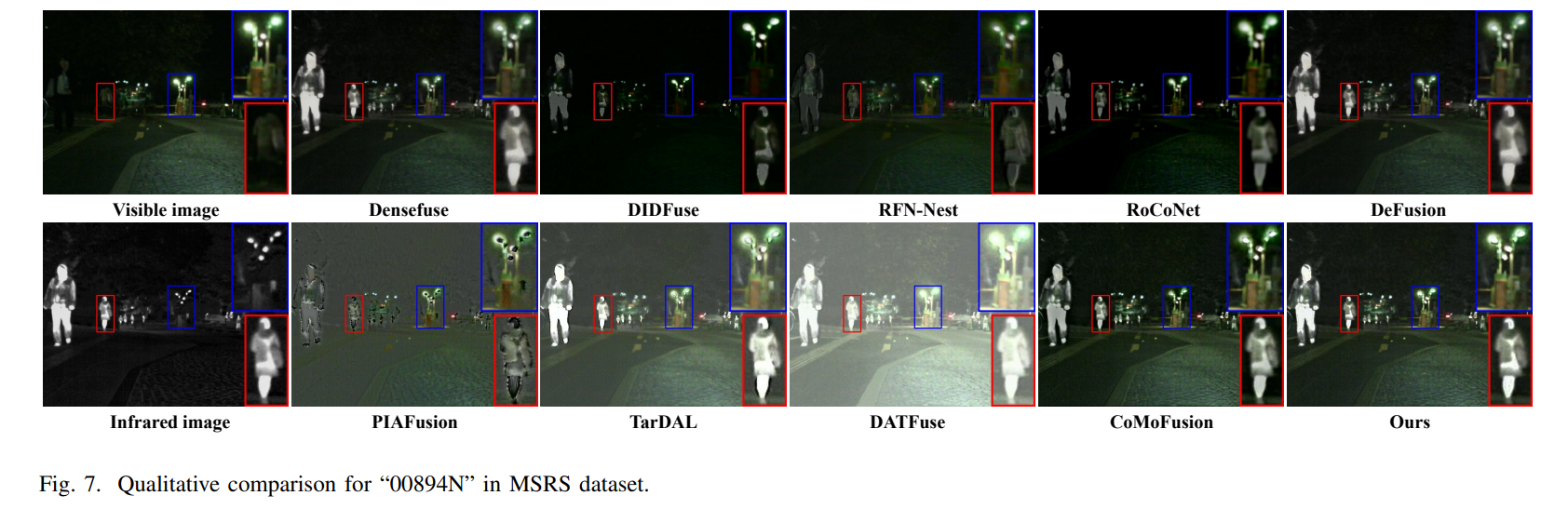
Experiment
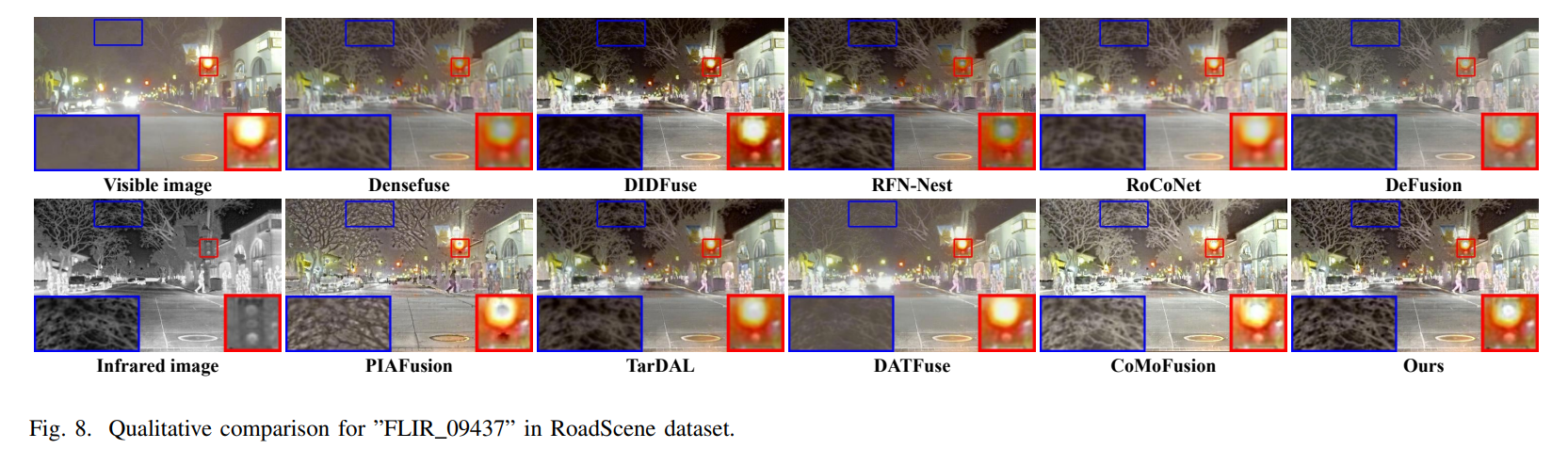
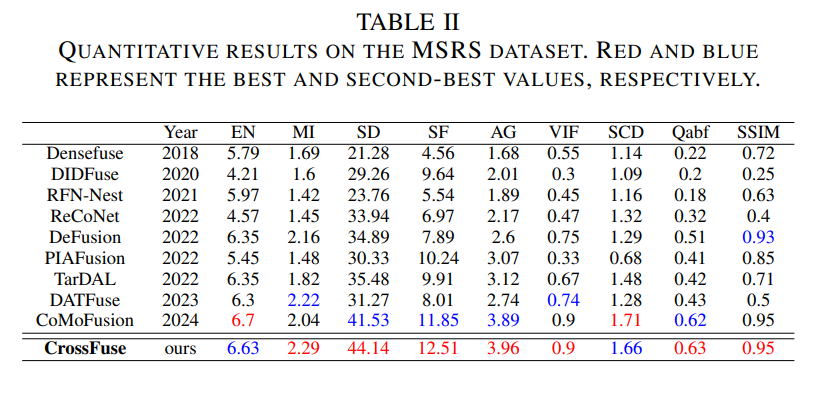

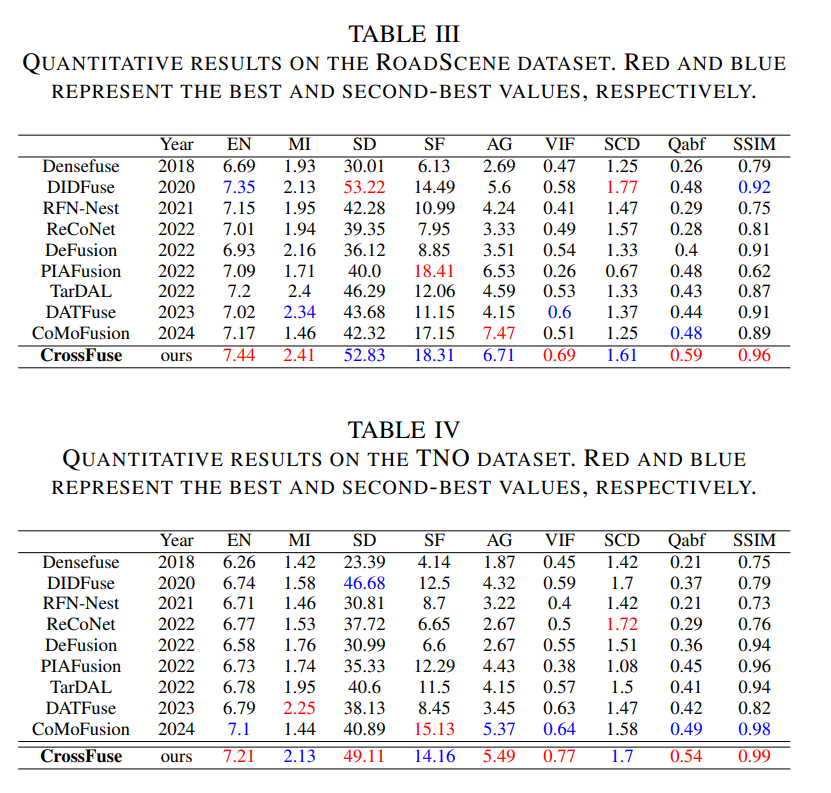
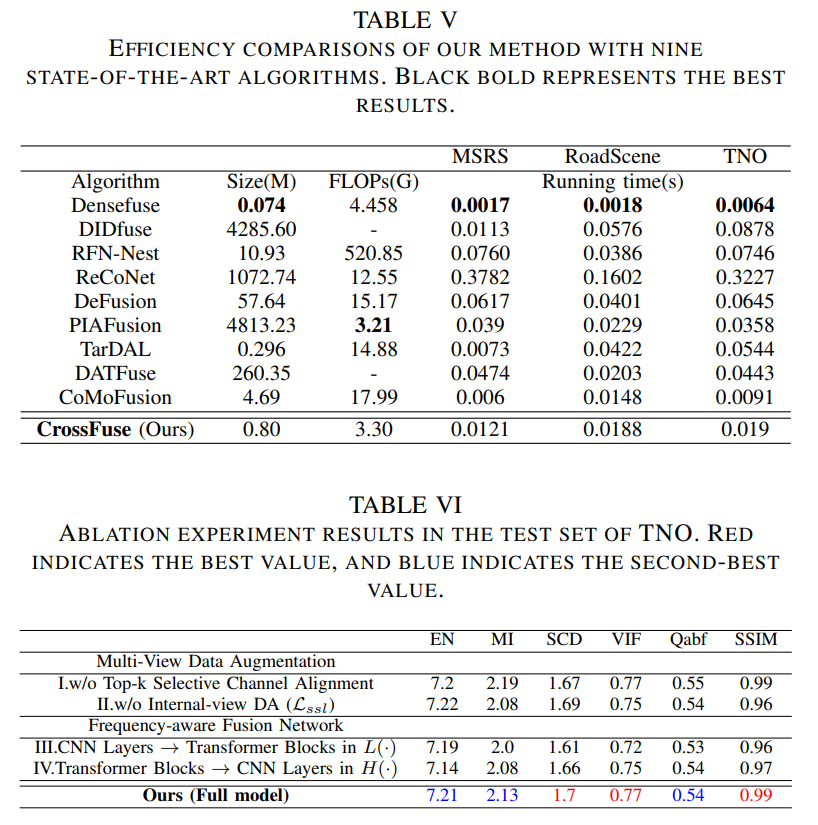
Conclusion
In this paper, we delve into the challenges posed by OOD data in infrared-visible fusion for real-world applications. We put forward an efficient image fusion framework based on multi-view data augmentation,which incorporates Top-K selective channel alignment and weak-aggressive augmentation techniques for both external-view and internal-view data augmentation. This strategy augments the generalization and robustness of our model, enabling it to adeptly handle the OOD data challenges commonly encountered in practical scenarios. Extensive experiments corroborate that our framework attains superior fusion performance across diverse data distributions, substantially propelling infrared-visible fusion for real-world applications. In future research, we intend to concentrate on exploring more efficacious methods to further grapple with OOD challenges, enhance model performance, and augment its deployment in real-world scenarios. Beyond image fusion, the core tenets of cross-domain alignment and multi-view augmentation hold the promise of benefiting other tasks, such as object detection, semantic segmentation, and image superresolution. These tasks could also profit from enhanced data consistency and improved cross-domain learning. Our future endeavors will involve adapting and extending our approach to optimize performance for these tasks while contending with their specific challenges.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab