
Abstract
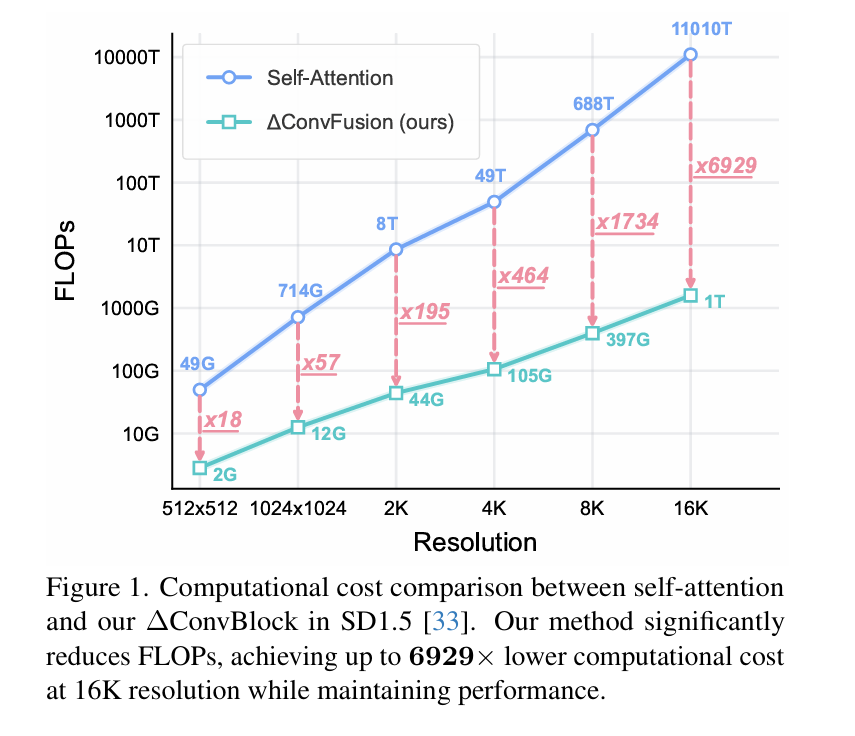
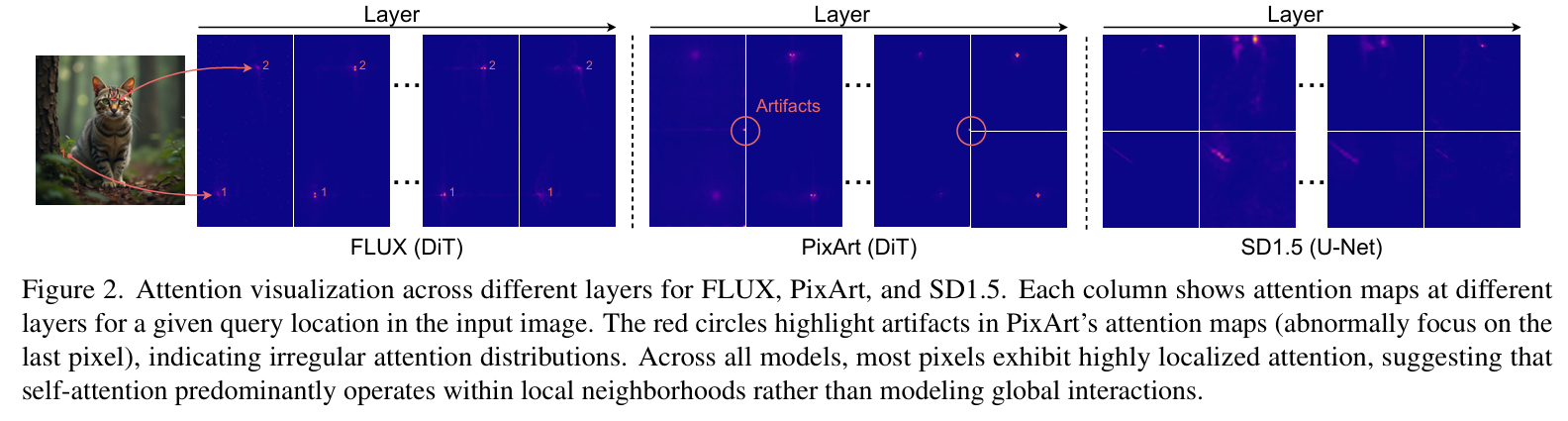
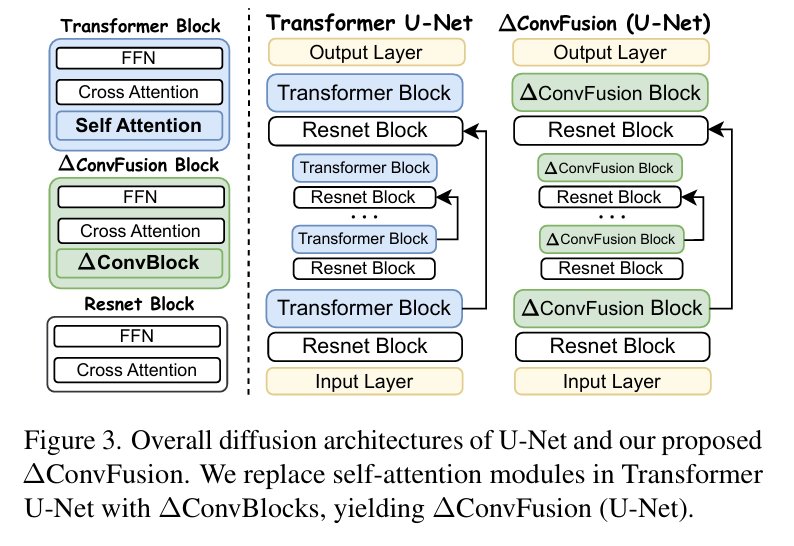
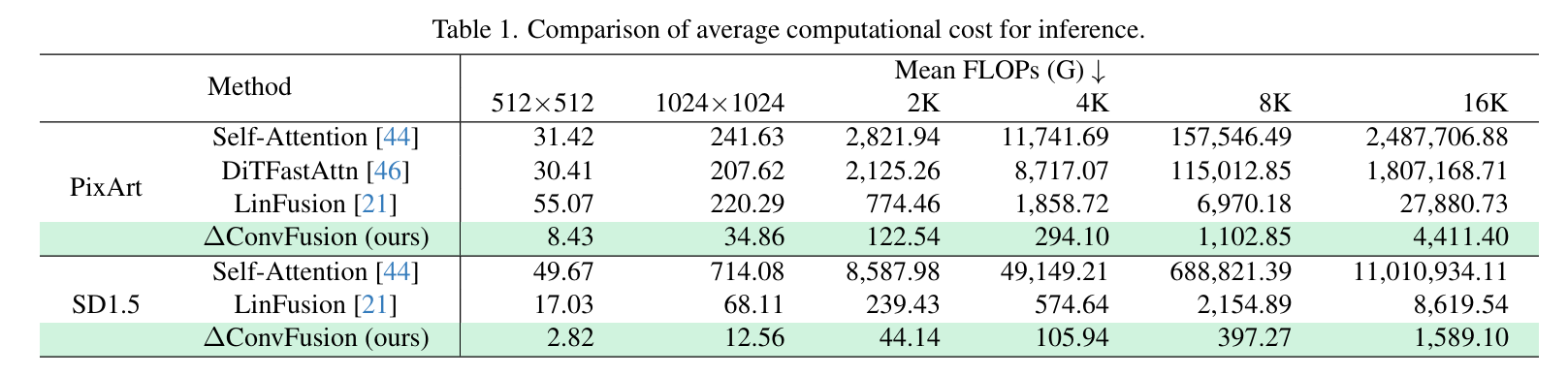
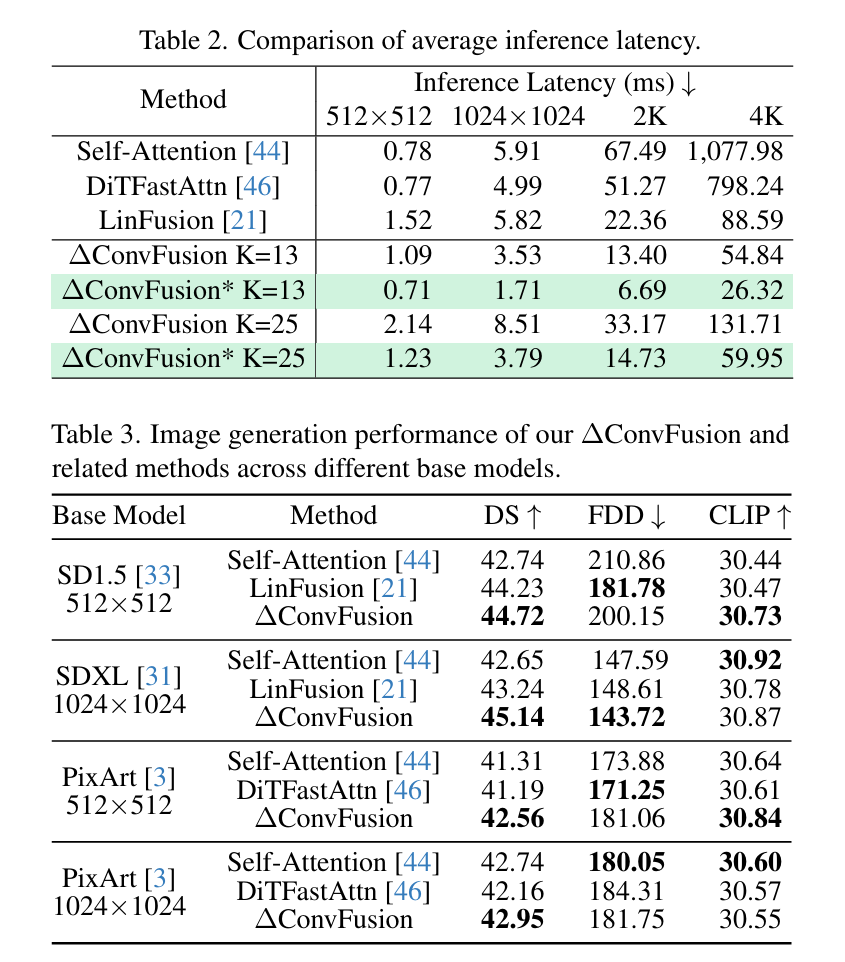
Contemporary diffusion models built upon U-Net or Diffusion Transformer (DiT) architectures have revolutionized image generation through transformer-based attention mechanisms. The prevailing paradigm has commonly employed self-attention with quadratic computational complexity to handle global spatial relationships in complex images, thereby synthesizing high-fidelity images with coherent visual this http URL to conventional wisdom, our systematic layer-wise analysis reveals an interesting discrepancy: self-attention in pre-trained diffusion models predominantly exhibits localized attention patterns, closely resembling convolutional inductive biases. This suggests that global interactions in self-attention may be less critical than commonly this http URL by this, we propose \(\Delta\)ConvFusion to replace conventional self-attention modules with Pyramid Convolution Blocks (\(\Delta\)ConvBlocks).By distilling attention patterns into localized convolutional operations while keeping other components frozen, \(\Delta\)ConvFusion achieves performance comparable to transformer-based counterparts while reducing computational cost by 6929\times and surpassing LinFusion by 5.42\times in efficiency--all without compromising generative fidelity.
Framework


Experiment


Conclusion
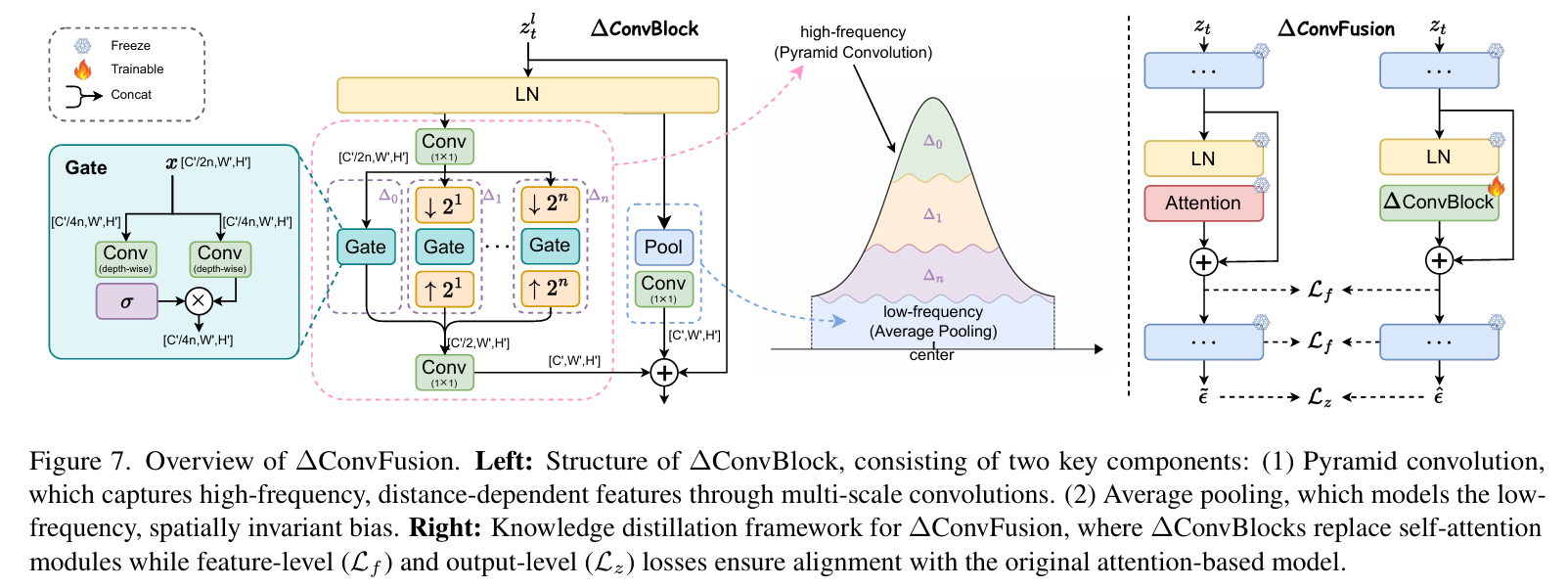
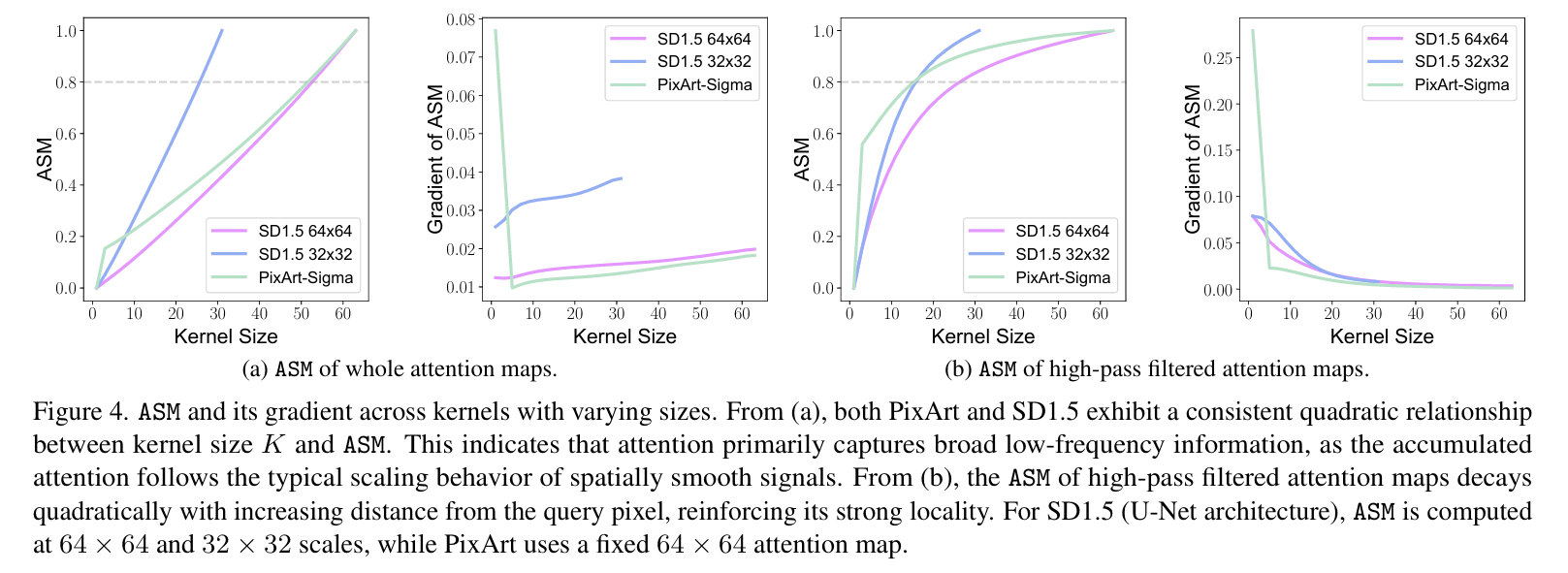
This work systematically analyzes the role of self-attention in diffusion models and studies whether global attention is necessary for effective image generation.Our study reveals that self-attention maps contain two key components: (1)a high frequency, distance-dependent signal, where the attention strength decays quadratically with increasing distance from the query pixel, exhibiting strong locality. (2) A low frequency global component, which manifests as a spatially invariant attention bias across the feature map. Based on this, we propose ∆ConvBlock, a novel module that decouples these complementary mechanisms through a dual-branch design: (1) Pyramid convolution operators capture localized high-frequency patterns using multi-scale receptive fields. (2) Adaptive average pooling layers approximate the global low-frequency bias. This structured decomposition enables ∆ConvBlock to preserve the functional properties of self attention while reducing its quadratic computational com plexity. Extensive experiments across DiT and U-Net-based diffusion models demonstrate that our approach maintains generation quality while significantly improving efficiency.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab