
Abstract
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physical robots. In these methods, the rewards from different criteria are normally summed to learn a scalar function. However, a scalar is less informative and may be insufficient to derive effective information for each reward channel from the complex hybrid rewards. In this work, we propose a novel reward-adaptive reinforcement learning method for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. The proposed method applies a multi-head critic to learn a separate value function for each reward component, leading to hybrid policy gradients. We further propose dynamic weight, allowing each component to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We show that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of HDPG.Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physical robots. In these methods, the rewards from different criteria are normally summed to learn a scalar function. However, a scalar is less informative and may be insufficient to derive effective information for each reward channel from the complex hybrid rewards. In this work, we propose a novel reward-adaptive reinforcement learning method for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. The proposed method applies a multi-head critic to learn a separate value function for each reward component, leading to hybrid policy gradients. We further propose dynamic weight, allowing each component to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We show that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of HDPG.
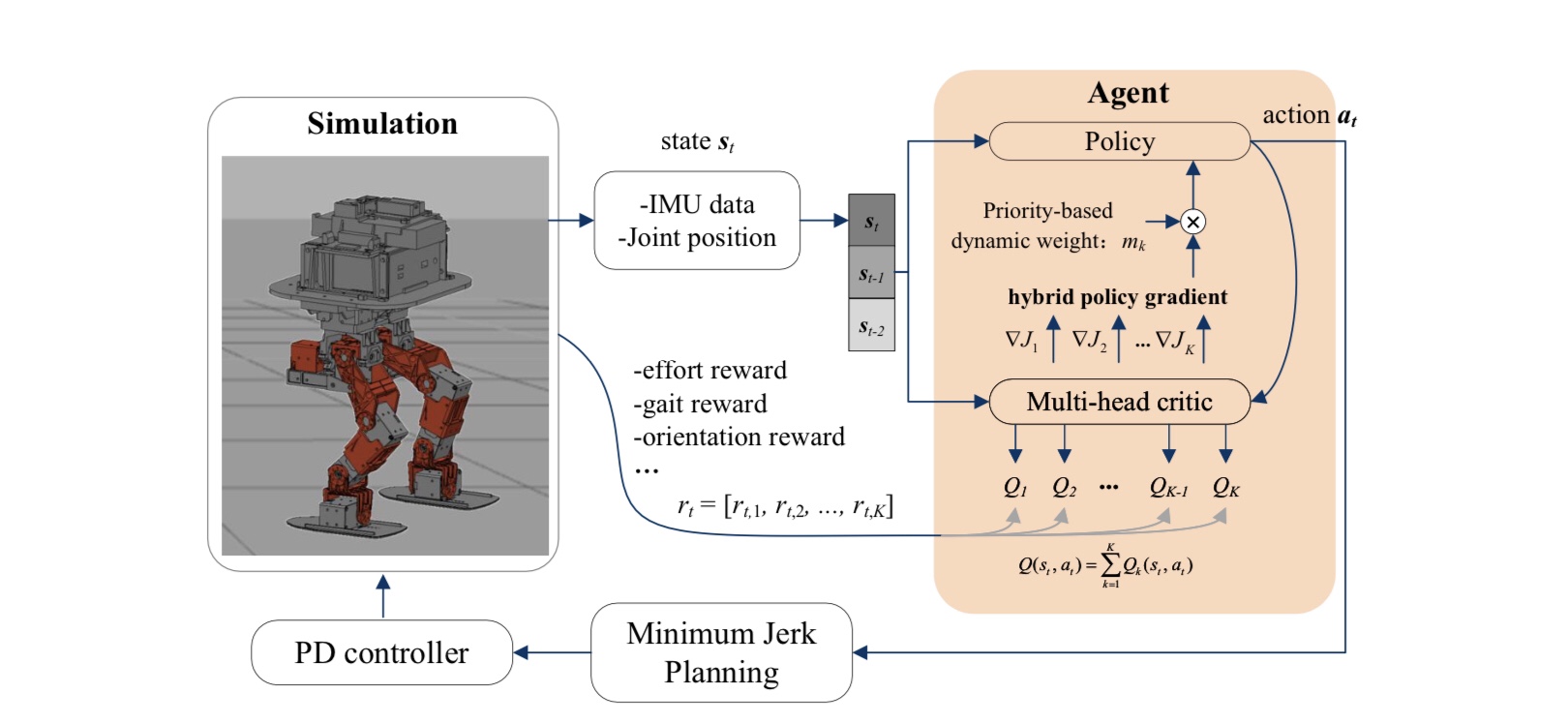
Framework

Experiment
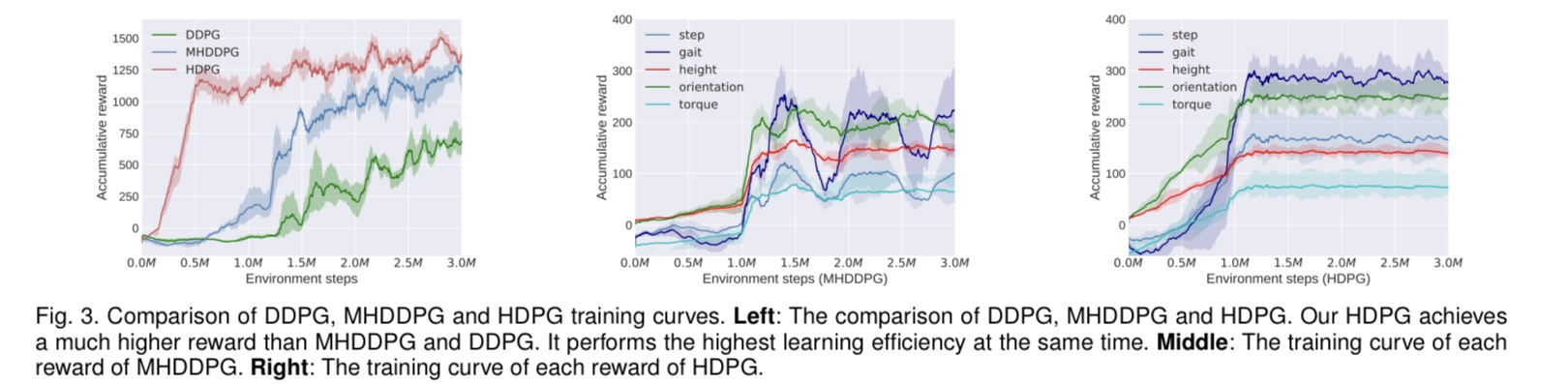
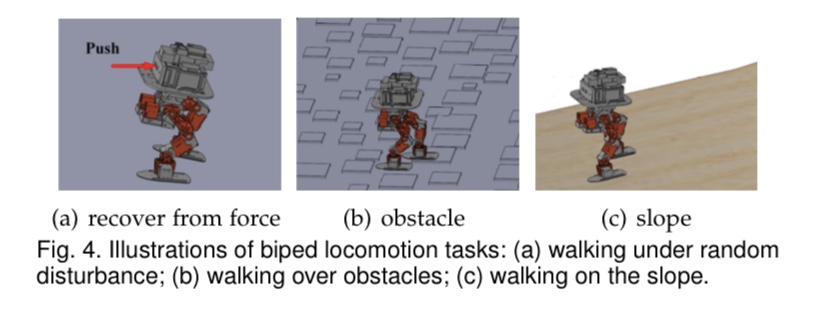
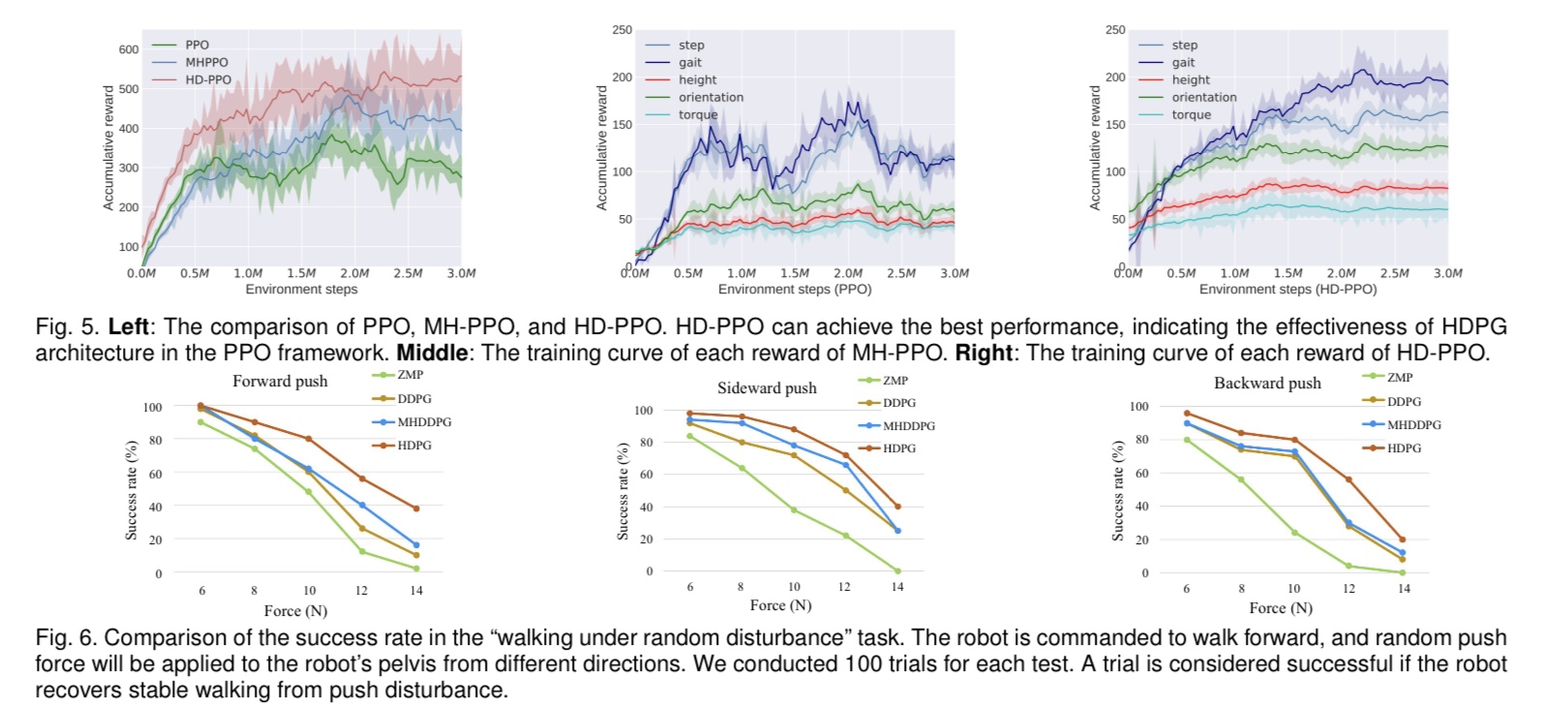

Video
Conclusion
In this work, we propose a reward-adaptive RL method for bipedal locomotion tasks called hybrid and dynamic policy gradient (HDPG) optimization. It decomposes the
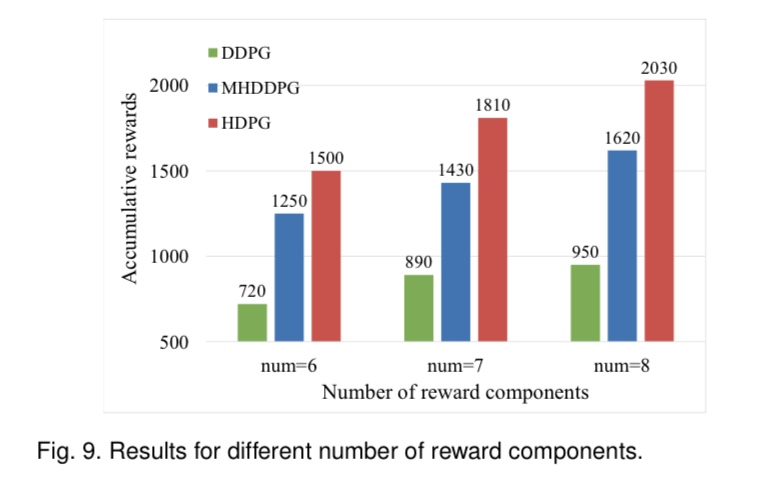
commonly adopted holistic polynomial reward function and introduces priority weights, enabling the agent to learn each reward component adaptively. Experimental evalu-
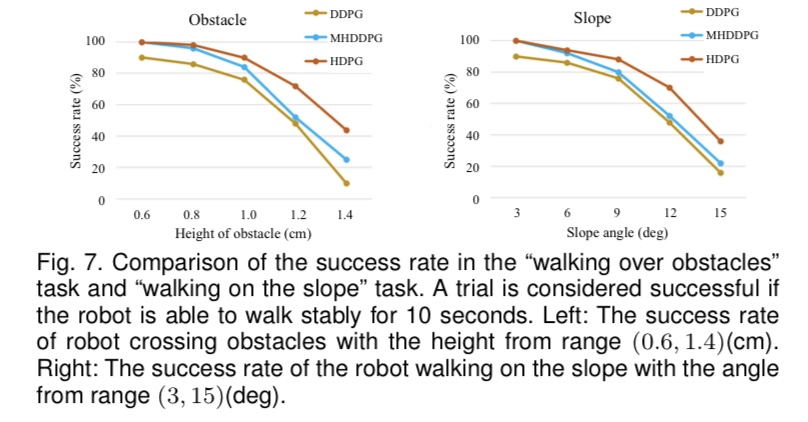
ation illustrates the effectiveness of HDPG by showing better performance on Gazebo simulation in perturbation walking challenges, walking over obstacles challenges, and
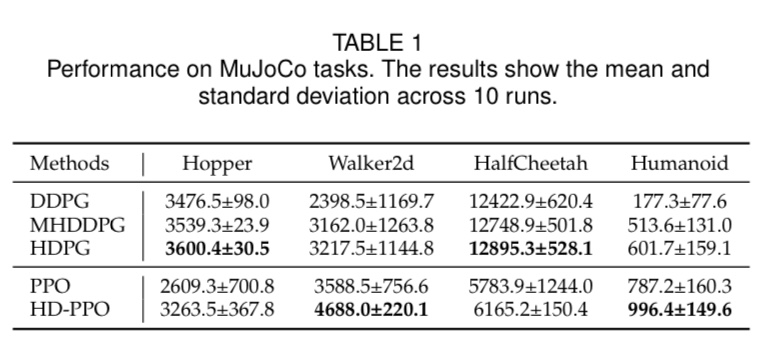
walking on undulating terrain challenges. With dynamics randomization, the policies trained in the simulation were successfully transferred to a physical robot. In addition, we further verify the generalization of HDPG on 3 MuJoCo tasks. Our future work will transfer the policies trained in the simulation into real physical robots in the challenges of walking across obstacles and undulating terrain.
Discussion. The proposed hybrid and dynamic weights could also be applied to stochastic policies, such as PPO. In that case, the hybrid reward architecture would firstly learn a separate state value V (st) instead of a state-action value Q(st, at). Based on this, the multi-channel advantage function and the policy gradient of each channel could then be calculated. Finally, dynamic weights could be used to weight these policy gradients to optimize the policy.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab