
Abstract
The rapid development of the autonomous driving industry has led to a significant accumulation of autonomous driving data. Consequently, there comes a growing demand for retrieving data to provide specialized optimization. However, directly applying previous image retrieval methods faces several challenges, such as the lack of global feature representation and inadequate text retrieval ability for complex driving scenes. To address these issues, firstly, we propose the BEV-TSR framework which leverages descriptive text as an input to retrieve corresponding scenes in the Bird’s Eye View (BEV) space. Then to facilitate complex scene retrieval with extensive text descriptions, we employ a large language model (LLM) to extract the semantic features of the text inputs and incorporate knowledge graph embeddings to enhance the semantic richness of the language embedding. To achieve feature alignment between the BEV feature and language embedding, we propose Shared Cross-modal Embedding with a set of shared learnable embeddings to bridge the gap between these two modalities, and employ a caption generation task to further enhance the alignment. Furthermore, there lack of well-formed retrieval datasets for effective evaluation. To this end, we establish a multi-level retrieval dataset, nuScenes-Retrieval, based on the widely adopted nuScenes dataset. Experimental results on the multi-level nuScenes-Retrieval show that BEV-TSR achieves state-of-the-art performance, eg, 85.78% and 87.66% top-1 accuracy on scene-to-test and text-to-scene retrieval respectively.
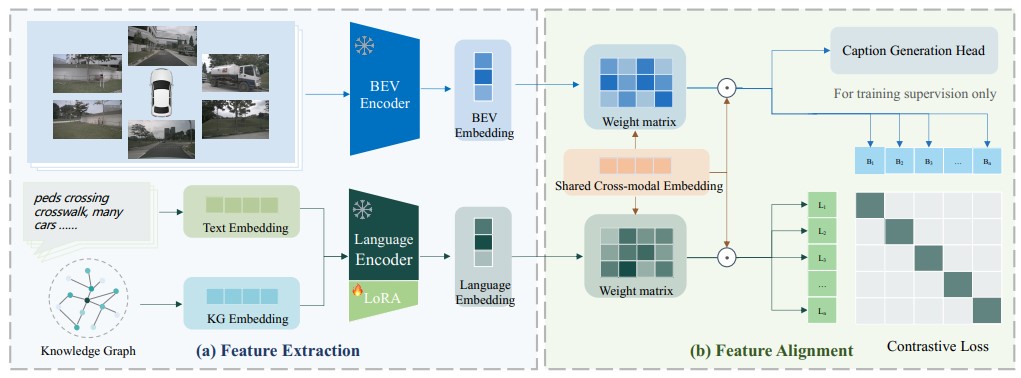
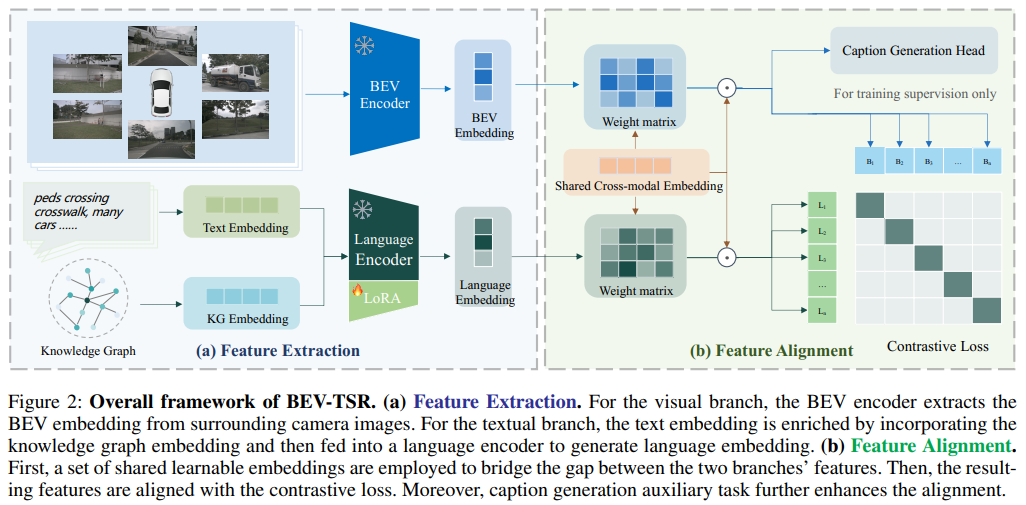
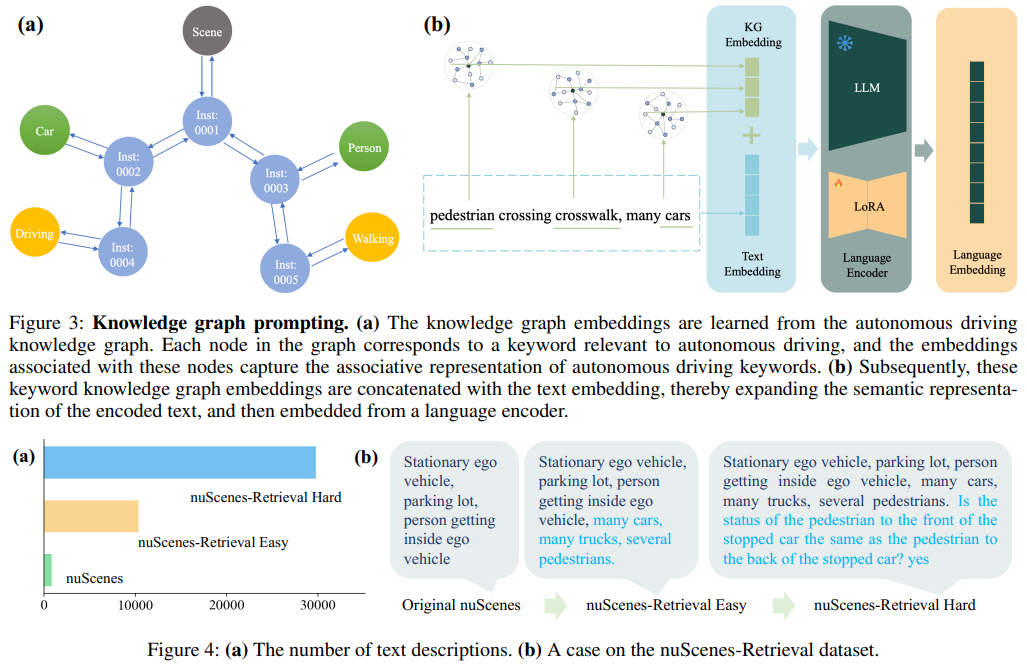
Framework

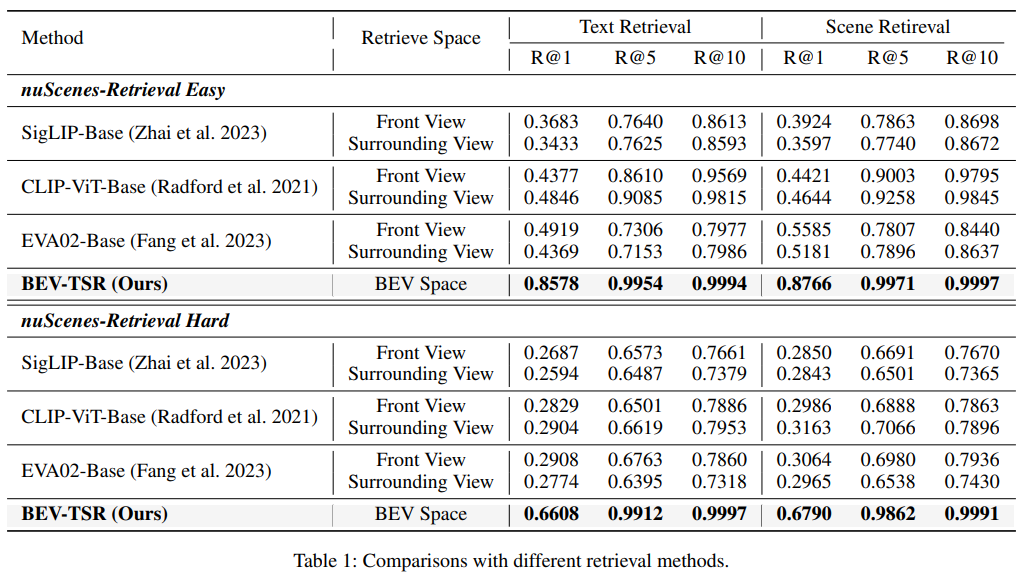
Experiment
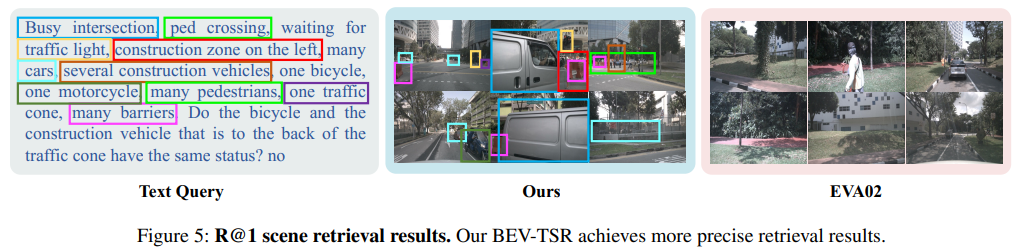
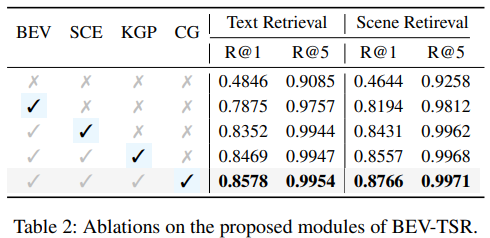
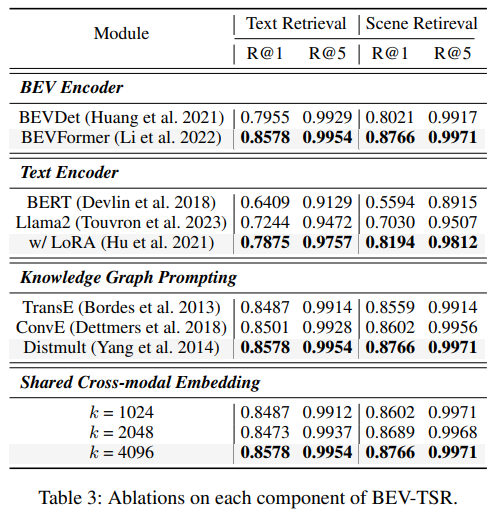
Conclusion
In this paper, we propose the novel BEV-TSR framework for text-scene retrieval in autonomous driving, which retrieves scenes in BEV space and demonstrates a significant capability to understand the global context and retrieve complex traffc scenarios. For text sentence representation, we leverage an LLM and incorporate knowledge graph embeddings to comprehensively understand complex textual descriptions, offering a higher level of semantic richness in language embedding. To align the features, we propose Shared Cross-modal Embedding, which utilizes a set of shared learnable embeddings to bridge the gap between the BEV features and language embeddings in different feature spaces. We also leverage a caption generation task to further enhance the alignment. Moreover, we establish a multi-level retrieval dataset, nuScenes-Retrieval, based on the nuScenes dataset, on which our BEV-TSR achieves state-of-the-art performance with remarkable improvement, and extensive ablation experiments demonstrate the effectiveness of our proposed method.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab