
Abstract
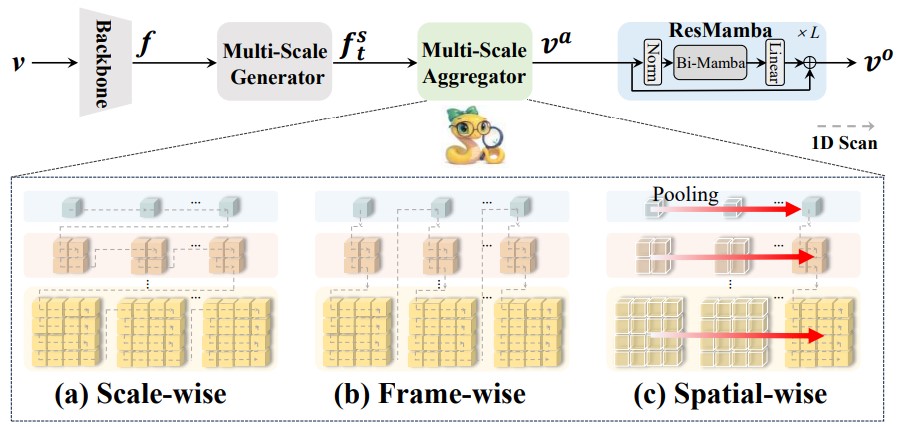
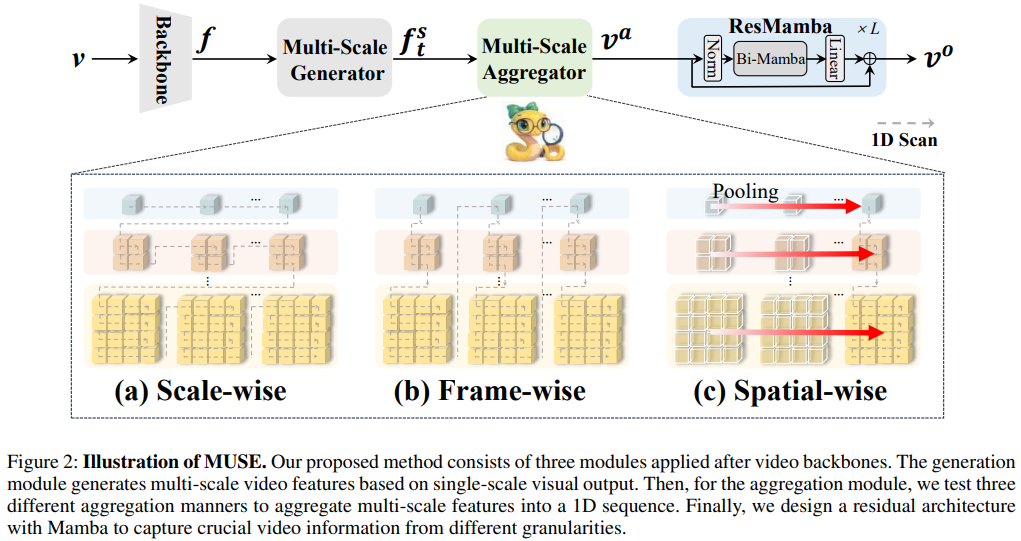
Text-Video Retrieval (TVR) aims to align and associate relevant video content with corresponding natural language queries. Most existing TVR methods are based on large-scale pre-trained vision-language models (e.g., CLIP). However, due to CLIP's inherent plain structure, few TVR methods explore the multi-scale representations which offer richer contextual information for a more thorough understanding. To this end, we propose MUSE, a multi-scale mamba with linear computational complexity for efficient cross-resolution modeling. Specifically, the multi-scale representations are generated by applying a feature pyramid on the last single-scale feature map. Then, we employ the Mamba structure as an efficient multi-scale learner to jointly learn scale-wise representations. Furthermore, we conduct comprehensive studies to investigate different model structures and designs. Extensive results on three popular benchmarks have validated the superiority of MUSE.
Framework

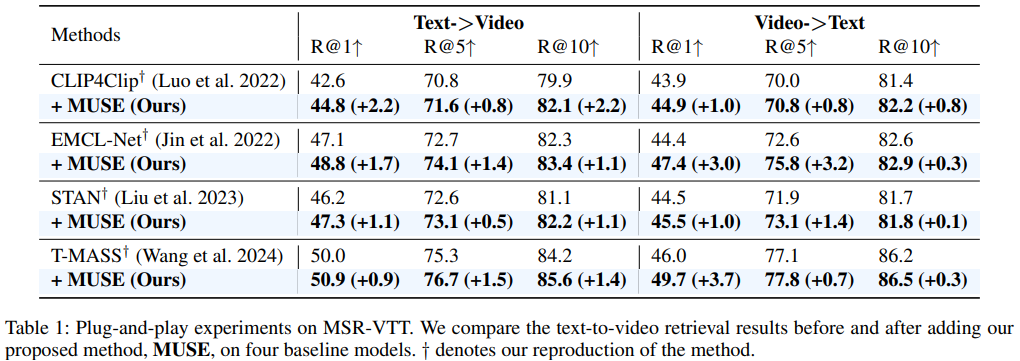
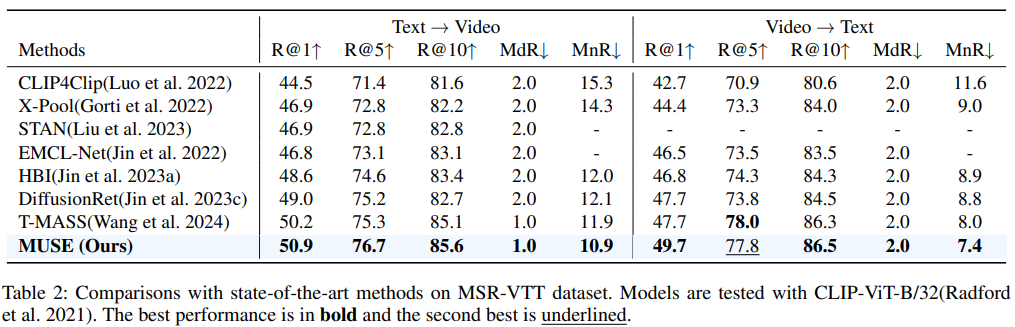
Experiment
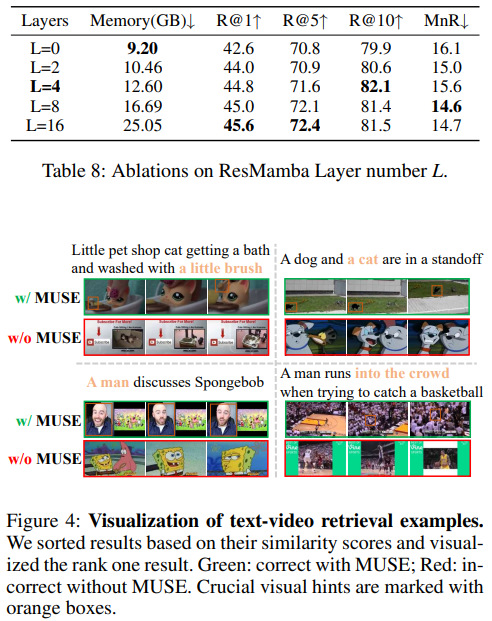
Conclusion
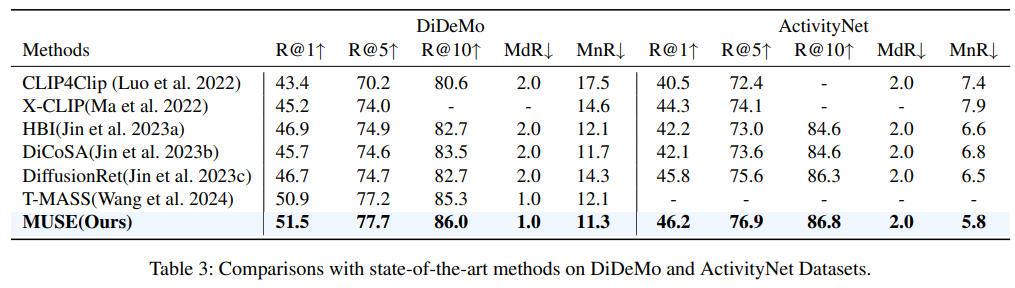
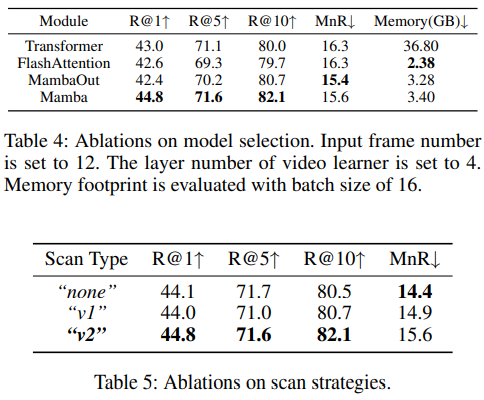
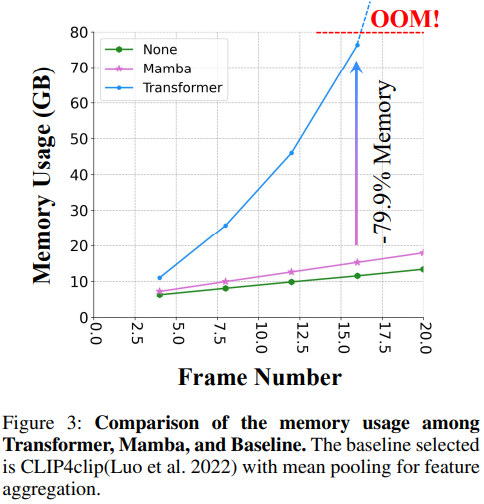
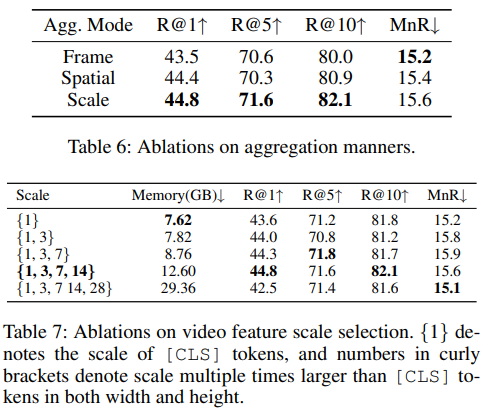
This paper presents MUSE acting as an effcient multiresolution learner for text-video retrieval. Based on the plain structure of the pre-trained CLIP model, we generate multiscale features by simply applying a feature pyramid on the last layer feature. For the cross-resolution feature integration, we leverage Mamba to achieve effective and effcient context modeling. Extensive experiments illustrate that MUSE achieves state-of-the-art performance and scalable plug-and-play characteristics.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Projects
- Computer Vision
- Multimodal
- Robotics
- Links
- Git-Lab