
Abstract
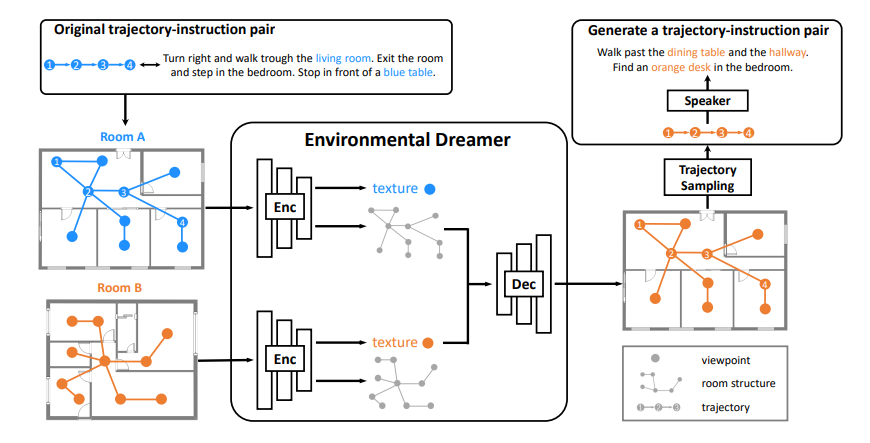
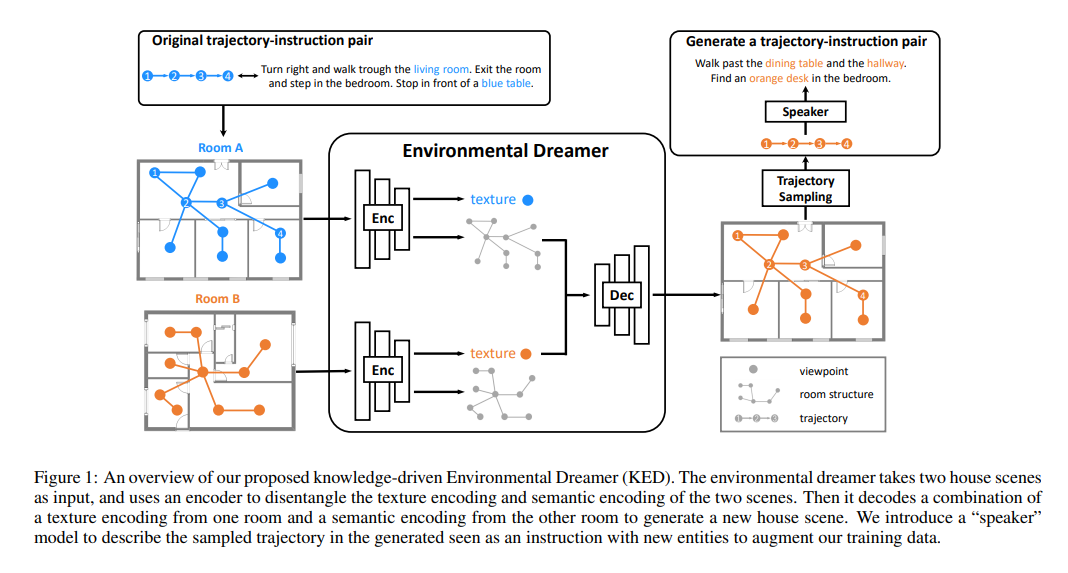
Vision-language navigation (VLN) requires an agent to perceive visual observation in a house scene and navigate step-by-step following natural language instruction. Due to the high cost of data annotation and data collection, current VLN datasets provide limited instruction-trajectory data samples. Learning vision-language alignment for VLN from limited data is challenging since visual observation and language instruction are both complex and diverse. Previous works only generate augmented data based on original scenes while failing to generate data samples from unseen scenes, which limits the generalization ability of the navigation agent. In this paper, we introduce the Knowledge-driven Environmental Dreamer (KED), a method that leverages the knowledge of the embodied environment and generates unseen scenes for a navigation agent to learn. Generating an unseen environment with texture consistency and structure consistency is challenging. To address this problem, we incorporate three knowledge-driven regularization objectives into the KED and adopt a reweighting mechanism for self-adaptive optimization. Our KED method is able to generate unseen embodied environments without extra annotations. We use KED to successfully generate 270 houses and 500K instruction-trajectory pairs. The navigation agent with the KED method outperforms the state-of-the-art methods on various VLN benchmarks, such as R2R, R4R, and RxR. Both qualitative and quantitative experiments prove that our proposed KED method is able to high quality augmentation data with texture consistency and structure consistency.
Framework
Experiment
Conclusion
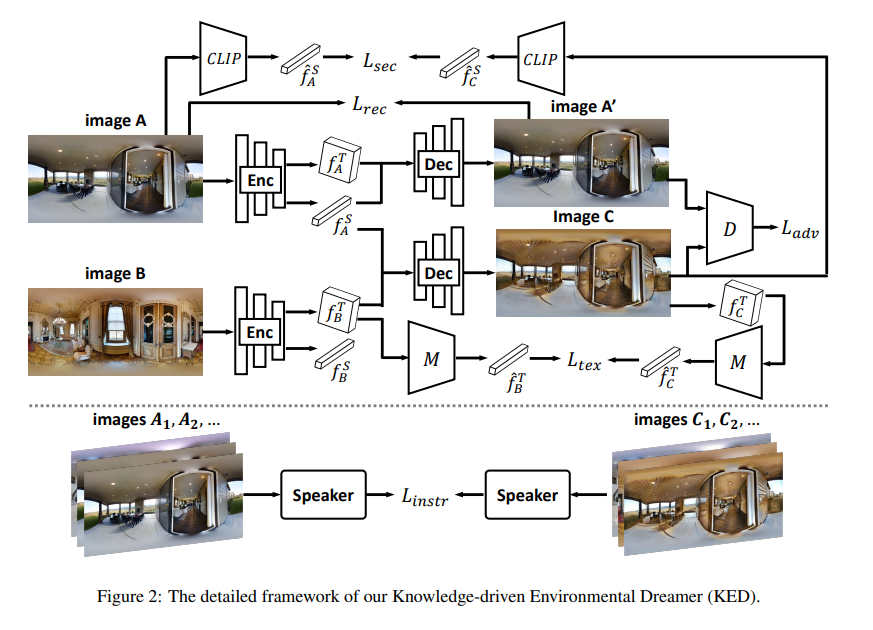
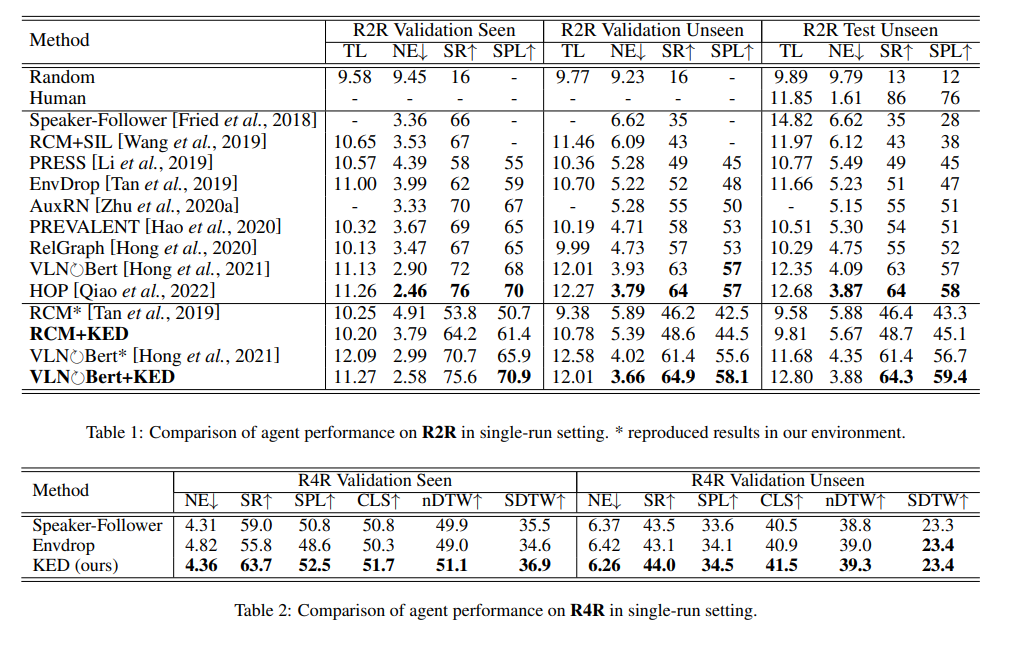
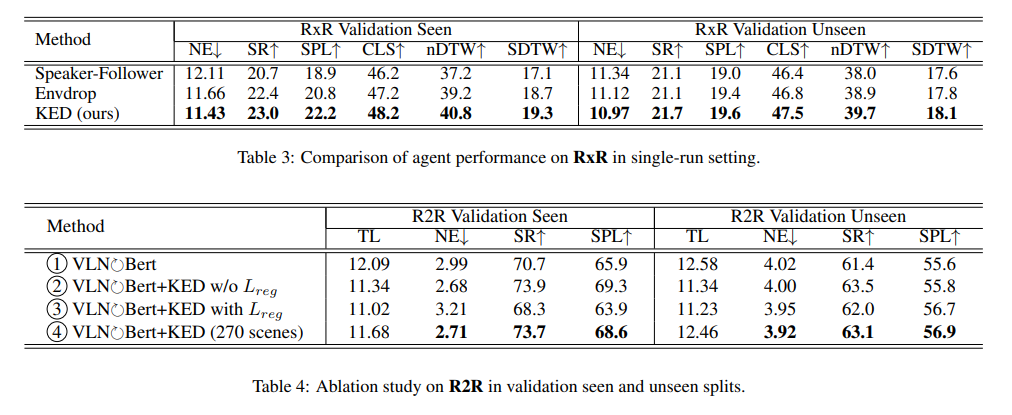
In this paper, we propose Knowledge-driven Environmental Dreamer (KED) to generate unseen scenes for agents to learn. KED is required to ensure texture consistency and structure consistency in generating new scenes. We propose three novel reconstruction objectives that leverage knowledge from pertained CLIP model and the “speaker” model to regularize the optimization of KED. Our experimental results reveal that the augmentation data generated by KED is able to signifcantly improve the performance of the navigation agent. Both quantitatively and qualitatively analysis infers that the knowledge-driven environmental dreamer is able to generate high-quality augmentation data.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Links
- Git-Lab