
Abstract
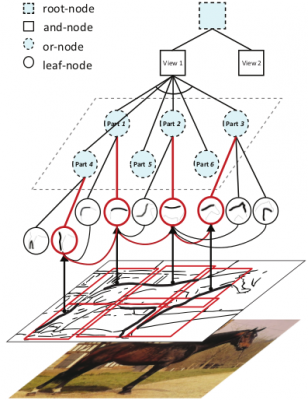
This paper investigates a novel reconfigurable part-based model, namely And-Or graph model, to recognize object shapes in images, as Fig. 1 shows.
The proposed model consists of four layers:
- Leaf-nodes: local classifiers for detecting contour fragments;
- Or nodes: switches to activate one of its child leaf-nodes, making the model reconfigurable during inference;
- And-nodes capture holistic shape deformations;
- Root-node is also an or-node, which activates one of its child and-nodes to deal with large global variations (e.g. different poses and views).
We discriminatively train the And-Or model from weakly annotated data by proposing a non-convex optimization algorithm. This algorithm iteratively determines the latent model structures (e.g. the nodes and their layouts) along with the parameter learning.
Framework
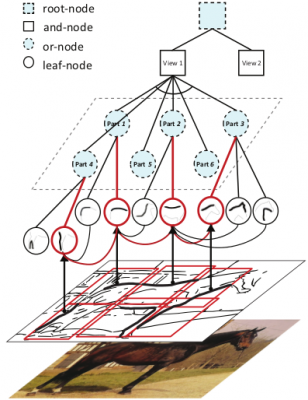
Fig. 1 An example of our And-Or graph model.
Experiment
We validate our model on a new shape database, SYSU-Shapes, as well as other two public databases: UIUCPeople [1] and INRIA-Horse [2], and show the superior performances over the state-of-the-art methods.
Experiment I: SYSU-Shape database
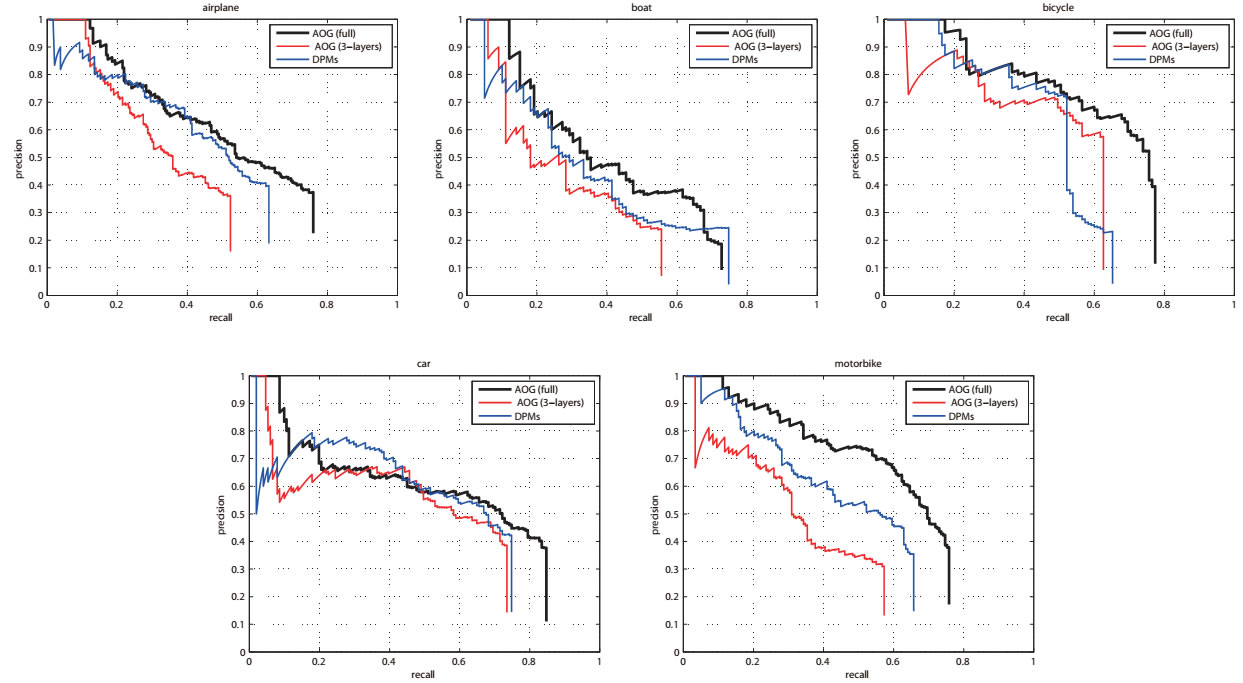
Precision-Recall (PR) curves on the SYSU-Shape dataset.DPM refers to the well acknowledged deformable part-based models (DPMs) [5].
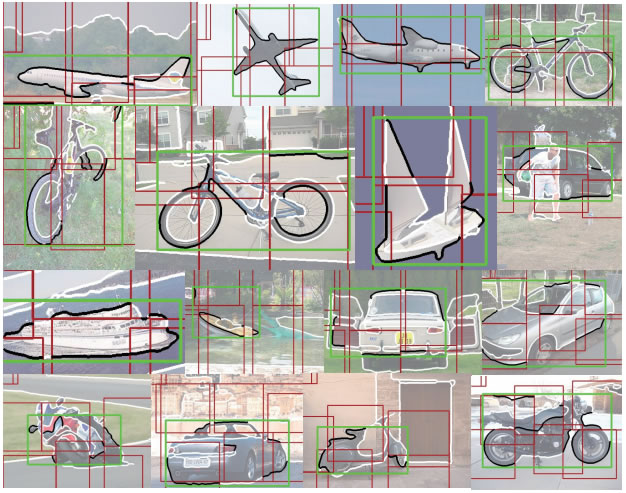
A few typical object shape detections generated by our approach on the SYSU-Shape dataset. The localized contours are highlighted by black; the green boxes and red boxes indicate detected shapes and their parts, respectively.
| Method | Airplane | Bicycle | Boat | Car | Motorbike | Mean AP |
|---|---|---|---|---|---|---|
| AOG (full) | 0.520 | 0.623 | 0.419 | 0.549 | 0.583 | 0.539 |
| AOG (3-layers) | 0.348 | 0.482 | 0.288 | 0.466 | 0.333 | 0.383 |
| DPMs | 0.437 | 0.488 | 0.365 | 0.509 | 0.455 | 0.451 |
Detection accuracy on the SYSU-Shape dataset.
Experiment II: UIUC-People dataset
A few typical object shape detections by applying our method on the UIUC-People database [36]. The localized contours are highlighted by black; the green boxes and red boxes indicate detected human and parts, espectively. Two failure detections are indicated by the blue boxes.
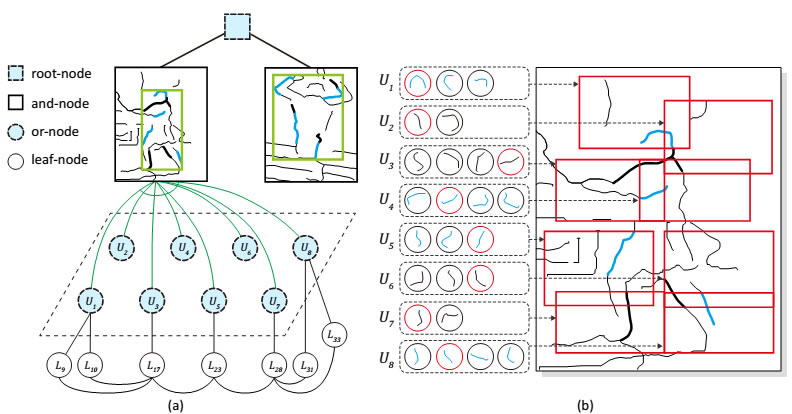
The trained And-Or graph model with the UIUC-People dataset. (a) Visualizes the model of 4 layers. (b) Exhibits leaf-nodes associated with or-nodes, U1, . . . , U8. A real detection case with the activated leaf-nodes are highlighted by red.
| Method | Accuracy |
|---|---|
| AOG model | 0.708 |
| Wang et al. [3] | 0.668 |
| Andriluka et al. [4] | 0.506 |
| Felz et al. [5] | 0.486 |
| Bourdev et al. [6] | 0.458 |
Comparisons of detection accuracies on the UIUC-people dataset.
Experiment III: INRIA Horse dataset
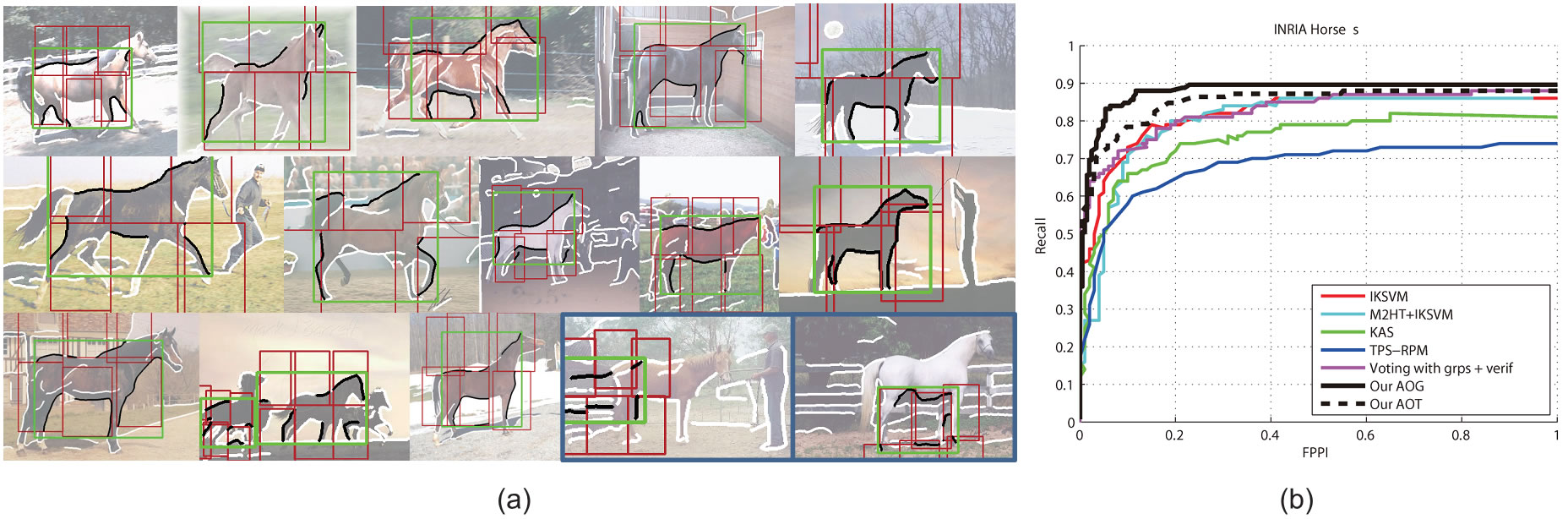
Results on the INRIA-Horse database. (a) shows several detected shapes by our method, where the localized contours are highlighted by black, and two failure detections are indicated by the blue boxes. (b) shows the quantitative results with the recall-FPPI measurement.
Experiment IV (Download PPT)
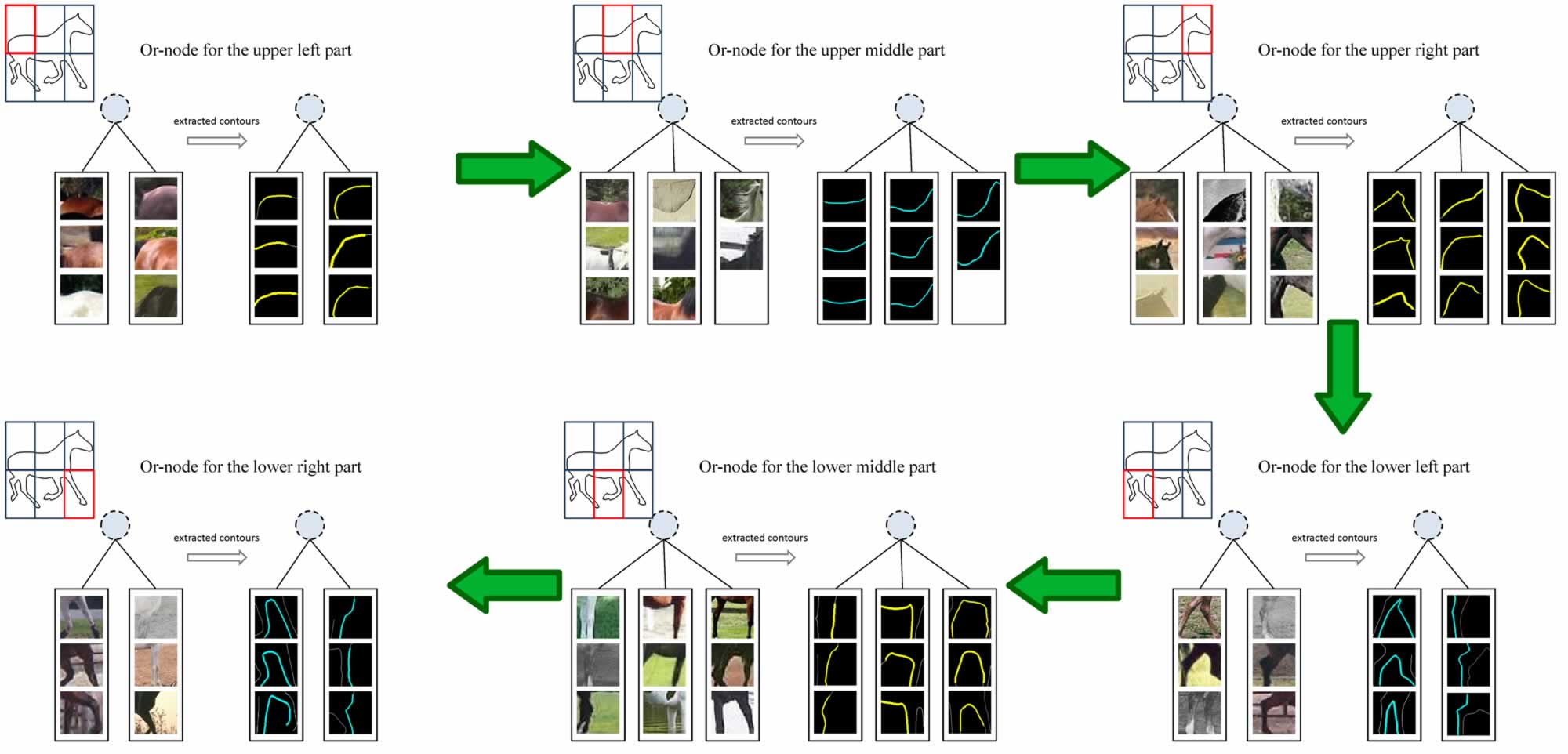
It would be good to generate visualizations to help understand what is being learned by various leaf nodes for various parts. One way to do this is simply visualize image patches across the training data for any given (Or-node, Leaf Node) combination.
For example, suppose you are training a horse detector. Lets say you have a Or-node associated with the head of the horse. The “head” node has various leaves to account for changes in appearance of the head. For each of the leaves, keep a track of training images on which that leaf fires.
References
References
- D. Tran and D. Forsyth, Improved human parsing with a full relational model, In Proc. of European Conference on Computer Vision (ECCV), 2010.
- F. Jurie and C. Schmid, Scale-invariant Shape Features for Recognition of Object Categories, In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2004.
- Y. Wang, D. Tran, and Z. Liao, Learning Hierarchical Poselets for Human Parsing, In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
- M. Andriluka, S. Roth, and B. Schiele, Pictorial structures revisited: People detection and articulated pose estimation, In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
- P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan, Object Detection with Discriminatively Trained Part-based Models, IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9): 1627-1645, 2010.
- L. Bourdev, S. Maji, T. Brox, and J. Malik, Detecting people using mutually consistent poselet activations, In Proc. of European Conference on Computer Vision (ECCV), 2010.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Links
- Git-Lab