
Abstract
Though quite challenging, leveraging large-scale unlabeled or partially labeled data in learning systems (e.g., model/classifier training) has attracted increasing attention due to its fundamental importance. To address this problem, many active learning (AL) methods have been proposed that employ up-to-date detectors to retrieve representative minority samples according to predefined confidence or uncertainty thresholds. However, these AL methods cause the detectors to ignore the remaining majority samples (i.e., those with low uncertainty or high prediction confidence). In this work, by developing a principled active sample mining (ASM) framework, we demonstrate that cost-effectively mining samples from these unlabeled majority data is key to training more powerful object detectors while minimizing user effort. Specifically, our ASM framework involves a switchable sample selection mechanism for determining whether an unlabeled sample should be manually annotated via AL or automatically pseudo-labeled via a novel self-learning process. The proposed process can be compatible with mini-batch based training (i.e., using a batch of unlabeled or partially labeled data as a one-time input) for object detection. In this process, the detector, such as a deep neural network, is first applied to the unlabeled samples (i.e., object proposals) to estimate their labels and output the corresponding prediction confidences. Then, our ASM framework is used to select a number of samples and assign pseudo-labels to them. These labels are specific to each learning batch, based on the confidence levels and additional constraints introduced by the AL process, and will be discarded afterward. Then, these temporarily labeled samples are employed for network fine-tuning. In addition, a few samples with low-confidence predictions are selected and annotated via AL. Notably, our method is suitable for object categories that are not seen in the unlabeled data during the learning process. Extensive experiments on two public benchmarks (i.e., the PASCAL VOC 2007/2012 datasets) clearly demonstrate that our ASM framework can achieve performance comparable to that of alternative methods but with significantly fewer annotations.
Framework
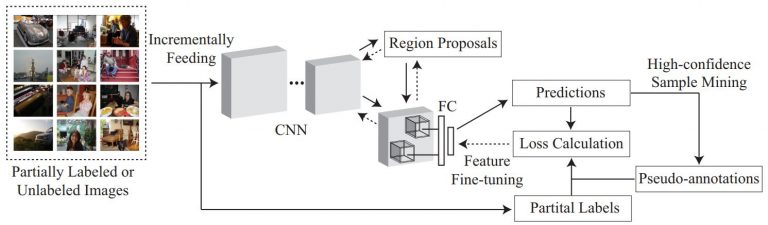
The proposed Active Sample Mining (ASM) framework for object detection. The arrows represent the work-flow, the full lines denote data flow in every mini-batch iteration, and the dashed lines represent data are processed intermittently.
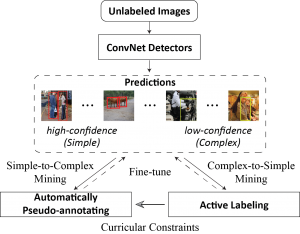
As illustrated, the main components in our ASM pipeline include region proposal generation and prediction, a high-confidence sample pseudo-labeling mode via the proposed self-learning process, and a low-confidence sample annotation mode via AL. Initially, we fine-tune the ConvNet object detectors using a small set of annotated samples to obtain an adequate initialization. Then, we leverage these initialized detectors to generate region proposals from unlabeled or partially labeled images and predict their labels with the corresponding confidence estimation. We further retrain the detectors through a one-off approach by temporally pseudo-labeling the top ranked (i.e., the high-confidence) region proposals in every mini-batch under the constraint of the self-learning curriculum. For the remaining samples, we intermittently annotate the informative samples through active user labeling under the constraint of the active learning curriculum and employ the newly annotated samples to further train and update the dual curricula to guide the self-learning process.
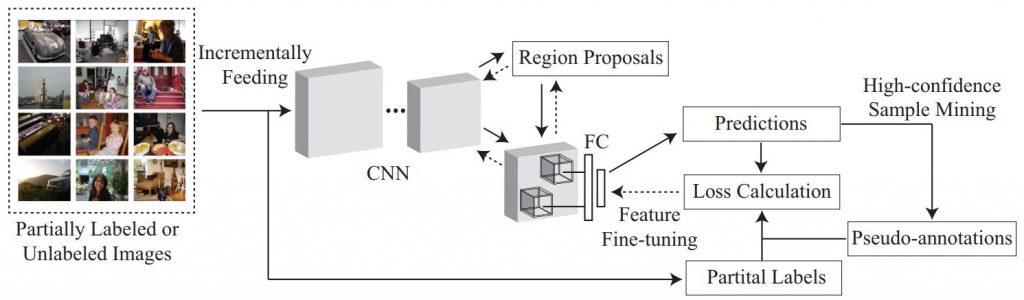
The workflow of the proposed high-confidence sample pseudo-labeling mode. The solid arrows represent forward propagation, and the dashed arrows represent backward propagation to fine-tune the network. Every mini-batch training iteration consists of three steps: i) region proposal generation and prediction from incrementally input partially labeled or unlabeled images, ii) pseudo-labeling based on high-confidence sample mining, and iii) feature fine-tuning by minimizing the loss between the predictions and training objectives (i.e., partial labels + pseudo-labels). Note that partial labels are absent when the images in a batch are all unlabeled.
Conclusion
We have introduced a principled active sample mining framework and demonstrated its effectiveness in mining the majority of unlabeled or partially labeled data to boost object detection. In our ASM framework, a self-learning process, integrated into the AL pipeline with a concise formulation, is employed for retraining the object detectors using accurately pseudo-labeled object proposals. Meanwhile, the remaining samples with low prediction confidence (i.e., high uncertainty) by the current detectors can be annotated} through the AL process, which contributes to generating reliable and diverse samples and gradually revising the self-learning process. By means of the proposed alternating optimization mechanism, our framework selectively and seamlessly switches between our self-learning process and the AL process for each unlabeled or partially labeled sample. Moreover, two curricula are introduced to guide the pseudo-labeling and annotation processes from dual perspectives. Thus, our ASM framework can be used to build effective CNN detectors that require fewer labeled training instances while achieving promising results. In the future, we plan to extend our framework to achieve improvements in other specific types of visual detection using unlabeled videos under the large-scale application scenarios.
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Links
- Git-Lab