

Abstract
Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [Poole et al. 2022]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
Framework
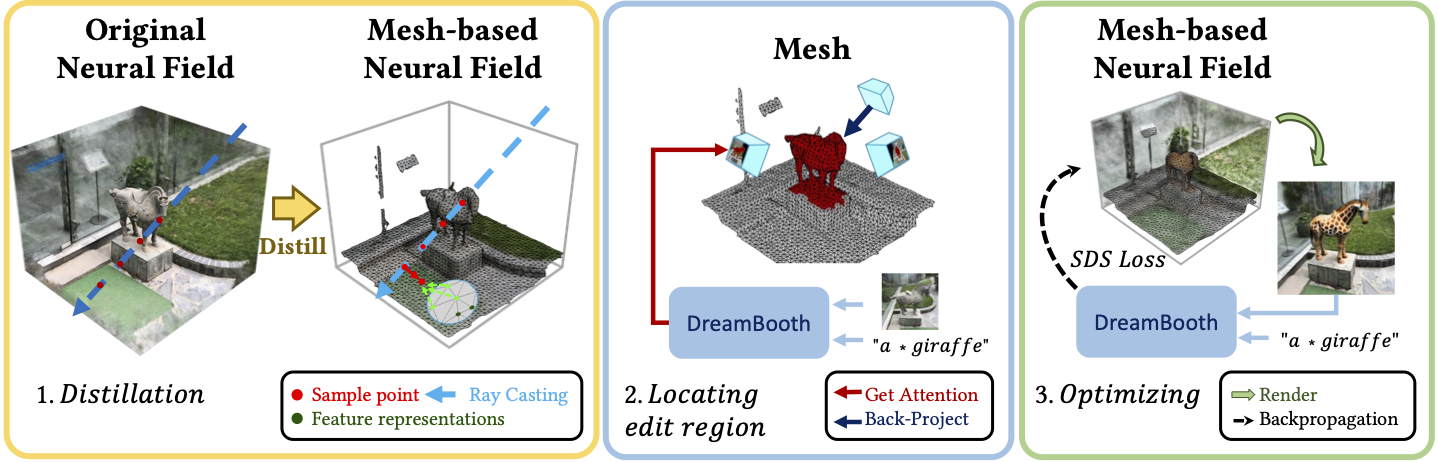
The inputs of our method are a set of posed images of a 3D scene to be edited and a text prompt for editing. Our goal is to change the shape and appearance of the object of interest in the original 3D scene according to the text prompt. Fig. 3 gives an example of turning a horse sculpture into a real giraffe. This task requires keeping the 3D contents irrelevant to the text prompt unchanged before and after editing.
The framework of DreamEditor is shown in Fig. 3, which consists of three stages.We first transform the original neural radiance field into a mesh-based neural field (Section 4.2), which enables us to achieve spatially-selective editing. In Section 4.3, we customize the T2I model to the input scene and use the cross-attention maps of it to locate the editing area in the 3D space according to the keywords in the text prompts. Finally, we edit the target object in the neural field under the control of text prompts through the T2I diffusion model (Section 4.4).
Experiment

Fig.3 presents a comparison of the results of our method with baselines. Instruct-N2N has difficulties in executing abstract operations (e.g. give an apron to a doll) and generates suboptimal results in some scenes. This is largely attributed to the fact that the Instruct-Pix2Pix model is not always reliable, and it operates on the full image. Therefore, Instruct-N2N changes the entire scene and may underperform when executing the instructions beyond the Instruct-Pix2Pix training set. The DreamBooth finetuning in D-DreamFusion* enables the T2I diffusion model to roughly learn the representation of the input objects, such as the toy in the first row and the man in the third. However, due to the complexity and diversity of real-world scenes, D-DreamFusion* cannot accurately represent a specific scene, leading the irrelevant regions of the scenes edited by D-DreamFusion* to change significantly, such as the deformation of the doll in the first row, the background in the second row. Moreover, all compared baselines can not guarantee the consistency of the scenes before and after editing in complex scenes (such as the garden in the second row), and their editing process may change the entire scene. In contrast, our method has more details and faithfully generates the content of the text prompts, while successfully maintaining the consistency of the input objects and scenes before and after editing.
Conclusion
In this paper, we present DreamEditor, a text-driven framework for editing 3D scenes represented by neural fields. Given a neural field and text prompts describing the desired edits, DreamEditor automatically identifies the editing region within the scene and modifies its geometry and texture accordingly. Experiments across a diverse range of scenes, including faces, objects, and large outdoor scenes, showcase the robust editing capabilities of DreamEditor to generate high-quality textures and shapes compared with other baselines while ensuring the edited scene remains consistent with the input text prompts.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China (NO. 62322608, 61976250), in part by the Open Project Program of State Key Laboratory of Virtual Reality Technology and Systems, Beihang University (No.VRLAB2023A01), and in part by the Guangdong Basic and Applied Basic Research Foundation (NO. 2020B1515020048).
References
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. 2022. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022).
Ayaan Haque, Matthew Tancik, Alexei A Efros, Aleksander Holynski, and Angjoo Kanazawa. 2023. Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions. arXiv preprint arXiv:2303.12789 (2023).
- hcp@sysu.edu.cn
- 广州市广州大学城外环东路132号

- Links
- Git-Lab